

|
The raw light fields data captured by plenotic cameras is a lenslet image from which sub-aperture images (or views) can be extracted. A matlab implementation of this decoding pipeline is available in the matlab light field toolbox. The decoding process which extracts the sub-aperture images from the lenslet image, includes several steps: de-vignetting, color de-mosaicking, conversion of the hexagonal to a rectangular sampling grid, and colour correction. We have first analyzed the different steps of this decoding pipeline to identify the issues which lead to various artefacts in the extracted views. This analysis led us to propose a method for white image guided color demosaicing of the lenslet image. Similarly, we have proposed an interpolation guided by the white image for aligning the micro-lens array and the sensor. [More here ...] |

|
Building upon the homography-based low rank approximation (HLRA) method we proposed (below) for light field compact representation and compression, we have, in collaboration with Trinity College Dublin, developed a method for capturing High Dynamic Range (HDR) light fields with dense viewpoint sampling from multiple exposures. The problem of recovering saturated areas is formulated as a Weighted Low Rank Approximation (WLRA) where the weights are defined from the soft saturation detection. The proposed WLRA method generalizes the matrix completion algorithm developed in the project (see below) for light fields inpainting.[More here ...] |
|
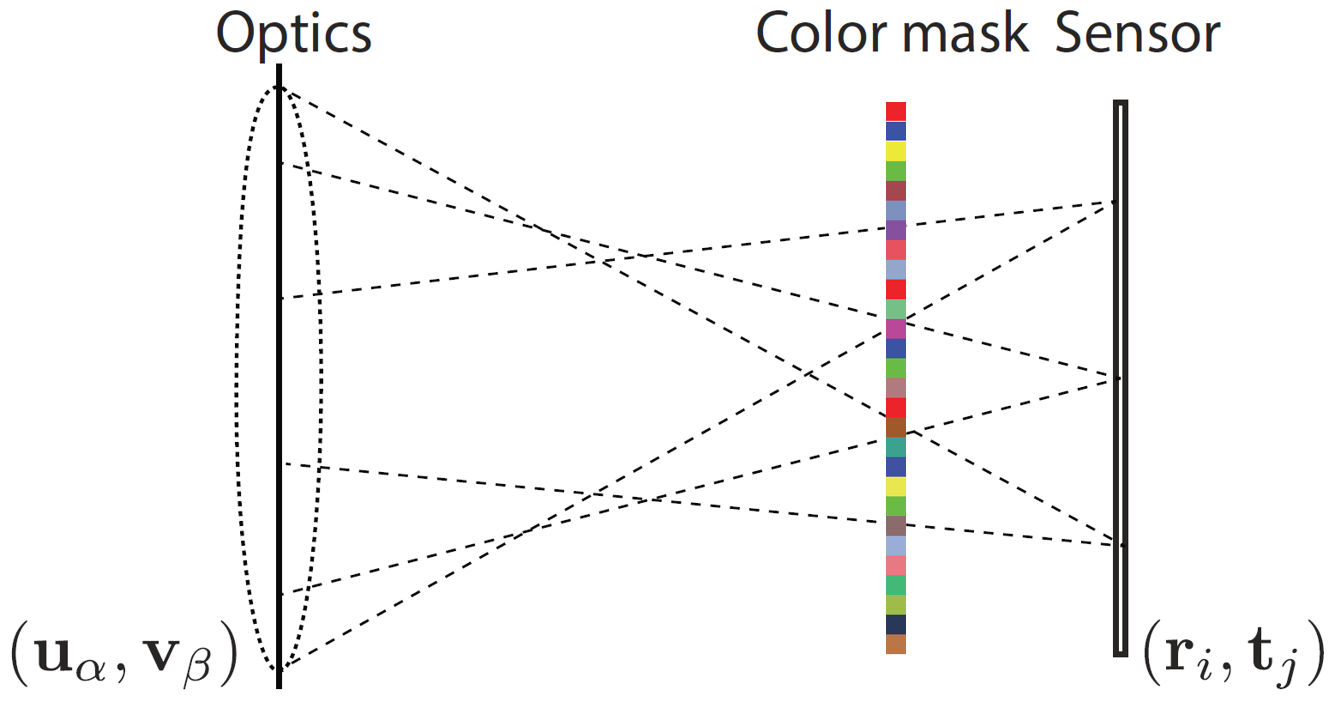
In collaboration with the Univ. of Linkoping, we have developed a compressive sensing framework for reconstructing the full light field of a scene captured using a single-sensor consumer camera. To achieve this, we use a color coded mask in front of the camera sensor. To further enhance the reconstruction quality, we utilize multiple shots by moving the mask or the sensor randomly. The compressed sensing framework relies on a training based dictionary over a light field data set. Numerical simulations show significant improvements in reconstruction quality over a similar coded aperture system for light field capture. [More here ...] |
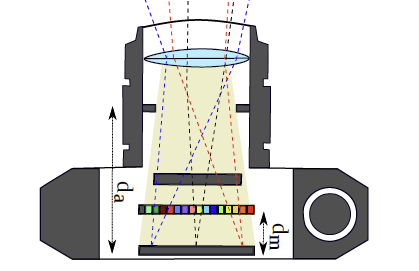
|
In collaboration with the Univ. of Linkoping, we have developed a novel compressed sensing (CS) algorithm and camera design for light field video capture using a single sensor consumer camera module. Unlike microlens light field cameras which sacrifice spatial resolution to obtain angular information, our CS approach is designed for capturing light field videos with high angular, spatial, and temporal resolution. The compressive measurements required by CS are obtained using a random color-coded mask placed between the sensor and aperture planes. The convolution of the incoming light rays from different angles with the mask results in a single image on the sensor; hence, achieving a significant reduction on the required bandwidth for capturing light field videos. We propose to change the random pattern on the spectral mask between each consecutive frame in a video sequence and extracting spatioangular- spectral-temporal 6D patches. Our CS reconstruction algorithm for light field videos recovers each frame while taking into account the neighboring frames to achieve significantly higher reconstruction quality with reduced temporal incoherencies, as compared with previous methods. Moreover, a thorough analysis of various sensing models for compressive light field video acquisition is conducted to highlight the advantages of our method. The results show a clear advantage of our method for monochrome sensors, as well as sensors with color filter arrays.. [More [here ...] |
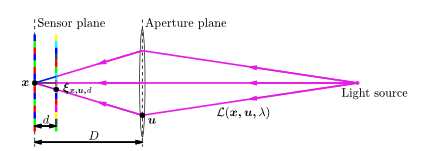
|
We have developed a simple variational approach for reconstructing color light fields (LFs) in the compressed sensing (CS) framework with very low sampling ratio, using both coded masks and color filter arrays (CFAs). A coded mask is placed in front of the camera sensor to optically modulate incomingrays, while a CFA is assumed to be implemented at the sensorlevel to compress color information. Hence, the LF coded projections, operated by a combination of the coded maskand the CFA, measure incomplete color samples with a three-times-lower sampling ratio than reference methods that assumefull color (channel-by-channel) acquisition. We then deriveadaptive algorithms to directly reconstruct the light field fromraw sensor measurements by minimizing a convex energy composed of two terms. The first one is the data fidelity term whichtakes into account the use of CFAs in the imaging model, and the second one is a regularization term which favors the sparse representation of light fields in a specific transform domain. Experimental results show that the proposed approach pro-duces a better reconstruction both in terms of visual qualityand quantitative performance when compared to referencereconstruction methods that implicitly assume prior color interpolation of coded projections. [preprint] |
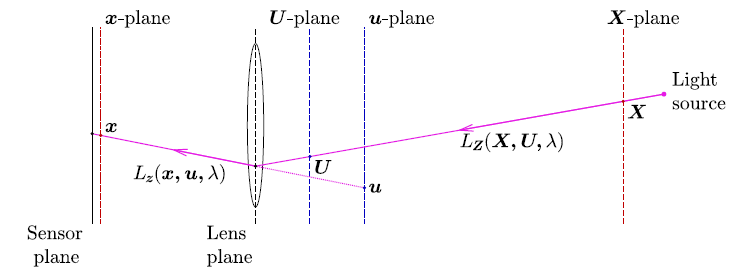
|
We have developed an all-in-one camera model that encompasses the architectures of most existing compressive-sensing light-field cameras, equipped with a single lens and multiple amplitude coded masks that can be placed at different positions between the lens and the sensor. The proposed model, named the equivalent multi-mask camera (EMMC) model, enables the comparison between different camera designs, e.g using monochrome or CFA-based sensors, single or multiple acquisitions, or varying pixel sizes, via a simple adaptation of the sampling operator. In particular, in the case of a camera equipped with a CFA-based sensor and a coded mask, this model allows us to jointly perform color demosaicing and light field spatioangular reconstruction. In the case of variable pixel size, it allows to perform spatial super-resolution in addition to angular reconstruction. While the EMMC model is generic and can be used with any reconstruction algorithm, we validate the proposed model with a dictionary-based reconstruction algorithm and a regularization-based reconstruction algorithm using a 4D Total- Variation-based regularizer for light field data. Experimental results with different reconstruction algorithms show that the proposed model can flexibly adapt to various sensing schemes. They also show the advantage of using an in-built CFA sensor with respect to monochrome sensors classically used in the literature. |

|
We have proposed a new design for single sensor compressive HDR light field cameras, combining multi- ISO photography with coded mask acquisition, placed in a compressive sensing framework. The proposed camera model is based on a main lens, a multi-ISO sensor and a coded mask located in the optical path between the main lens and the sensor that projects the coded spatio-angular information of the light field onto the 2D sensor. The model encompasses different acquisition scenarios with different ISO patterns and gains. Moreover, we assume that the sensor has a built-in color filter array (CFA), making our design more suitable for consumer-level cameras. We propose a reconstruction algorithm to jointly perform color demosaicing, light field angular information recovery, HDR reconstruction, and denoising from the multi-ISO measurements formed on the sensor. This is achieved by enabling the sparse representation of HDR light fields using an overcomplete HDR dictionary. We also provide two HDR light field data sets: one synthetic data set created using the Blender rendering software with two baselines, and a real light field data set created from the fusion of multi-exposure low dynamic range (LDR) images captured using a Lytro Illum light field camera. Experimental results show that, with a sampling rate as low as 2.67%, using two shots, our proposed method yields a higher light field reconstruction quality compared to the fusion of multiple LDR light fields captured with different exposures, and with the fusion of multiple LDR light fields captured with different ISO settings. [More here ...] |

|
Compressive light field photography enables light field acquisition using a single sensor by utilizing a color coded mask. This approach is very cost effective since consumerlevel digital cameras can be turned into a light field camera by simply placing a coded mask between the sensor and the aperture plane and solving an inverse problem to obtain an estimate of the original light field. We have developped a deep learning architecture for compressive light field acquisition using a color coded mask and a sensor with Color Filter Array (CFA). Unlike previous methods where a fixed mask pattern is used, our deep network learns the optimal distribution of the color coded mask pixels. The proposed solution enables end-to-end learning of the color-coded mask distribution, the CFA, and the reconstruction network. Consequently, the resulting network can efficiently perform joint demosaicing and light field reconstruction of images acquired with color-coded mask and a CFA sensor. Compared to previous methods based on deep learning with monochrome sensors, as well as traditional compressive sensing approaches using CFA sensors, we obtain superior color reconstruction of the light fields..[More here ...] |
 
|
We have addressed the problem of scene flow estimation from sparsely sampled video light fields. The scene flow estimation method is based on an affine model in the 4D ray space that allows us to estimate a dense flow from sparse estimates in 4D clusters. A dataset of synthetic video light fields created for assessing scene flow estimation techniques is also described. Experiments show that the proposed method gives error rates on the optical flow components that are comparable to those obtained with state of the art optical flow estimation methods, while computing a more accurate disparity variation when compared with prior scene flow estimation techniques. The dataset can be accessed [ here.] |

|
We have defined a local 4D affine model to represent scene flows, taking into account light field epipolar geometry. The model parameters are estimated per cluster in the 4D ray space. They are derivedb y fitting the model on initial motion and disparity estimatesobtained by using 2D dense optical flow estimation techniques. We have shown that the model is very effective for estimating scene flows from 2D optical flows. The model regularizes the optical flows and disparity maps, and interpolates disparity variation values in occluded regions. The proposed model allows us to benefit from deep learning-based 2D optical flow estimation methods while ensuring scene flow geometry consistency in the 4 dimensions of the light field. [preprint] |
 
|
We have addressed the problem of depth estimation for every viewpoint of a dense light field, exploiting information from only a sparse set of views. This problem is particularly relevant for applications such as light field reconstruction from a subset of views, for view synthesis and for compression. Unlike most existing methods for scene depth estimation from light fields, the proposed algorithm computes disparity (or equivalently depth) for every viewpoint taking into account occlusions. In addition, it preserves the continuity of the depth space and does not require prior knowledge on the depth range. The experiments show that, both for synthetic and real light fields, our algorithm achieves competitive performance to state-of-the-art algorithms which exploit the entire light field and usually yield to the depth map for the center viewpoint only. [More here ...] |

|
We have developed a learning based solution to disparity (depth) estimation for either densely or sparsely sampled light fields. Disparity between stereo pairs among a sparse subset of anchor views is first estimated by a fine-tuned FlowNet 2.0 network adapted to disparity prediction task. These coarse estimates are fused by exploiting the photo-consistency warping error, and refined by a Multi-view Stereo Refinement Network (MSRNet). The propagation of disparity from anchor viewpoints towards other viewpoints is performed by an occlusion-aware soft 3D reconstruction method. The experiments show that, both for dense and sparse light fields, our algorithm outperforms significantly the state-of-the-art algorithms, especially for subpixel accuracy. [More here ...] |

|
we propose a learning based depth estimation framework suitable for both densely and sparsely sampled light fields. The proposed framework consists of three processing steps: initial depth estimation, fusion with occlusion handling, and refinement. The estimation can be performed from a flexible subset of input views. The fusion of initial disparity estimates, relying on two warping error measures, allows us to have an accurate estimation in occluded regions and along the contours. In contrast with methods relying on the computation of cost volumes, the proposed approach does not need any prior information on the disparity range. Experimental results show that the proposed method outperforms state-of-the-art light fields depth estimation methods, including prior methods based on deep neural architectures. [More here ...] |

|
The availability of multiple views enables scene depth estimation, that can be used to generate 3D point clouds. The constructed 3D point clouds, however, generally contain distortions and artefacts primarily caused by inaccuracies in the depth maps. This paper describes a method for noise removal in 3D point clouds constructed from light fields. While existing methods discard outliers, the proposed approach instead attempts to correct the positions of points, and thus reduce noise without removing any points, by exploiting the consistency among views in a light-field. The proposed 3D point cloud construction and denoising method exploits uncertainty measures on depth values. We also investigate the possible use of the corrected point cloud to improve the quality of the depth maps estimated from the light field. [More here ...] |

|
Many computer vision applications rely on feature extraction and description, hence the need for computationally efficient and robust the 4D light field feature detectors and descriptors for applications using this imaging modality. We have proposed a novel light field feature extraction method in the scale-disparity space, based on a Fourier disparity layer representation. The proposed feature extraction takes advantage of both the Harris feature detector and circular gradient histogram descriptor, and is shown to yield more accurate feature matching, compared with the LiFF light field feature with low computational complexity. In order to evaluate the feature matching performance with the proposed descriptor, we generated synthetic light field dataset with ground truth matching points. Experimental results with synthetic and real-world datasets show that, our solution outperforms existing methods in terms of both feature detection robustness and feature matching accuracy. |

|
We have addressed the problem of temporal interpolation of sparsely sampled video light fields using dense scene flows. Given light fields at two time instants, the goal is to interpolate an intermediate light field to form a spatially, angularly and temporally coherent light field video sequence. We first compute angularly coherent bidirectional scene flows between the two input light fields. We then use the optical flows and the two light fields as inputs to a convolutional neural network that synthesizes independently the views of the light field at an intermediate time. In order to measure the angular consistency of a light field, we propose a new metric based on epipolar geometry. Experimental results show that the proposed method produces light fields that are angularly coherent while keeping similar temporal and spatial consistency as state-of-the-art video frame interpolation methods. [preprint; More here ...] |
|
|
We have developed an optical flow-based pipeline employing deep features extracted to learn residue maps for progressively refining the synthesized intermediate frame. We also propose a procedure for finetuning the optical flow estimation module using frame interpolation datasets, which does not require ground truth optical flows. This procedure is effective to obtain interpolation task-oriented optical flows and can be applied to other methods utilizing a deep optical flow estimation module. Experimental results demonstrate that our proposed network performs favorably against state-of-the-art methods both in terms of qualitative and quantitative measures.. [preprint; More here ...] |

|
We have developed a very lightweight neural network architecture, trained on stereo data pairs, which performs view synthesis from one single image. With the growing success of multi-view formats, this problem is increasingly relevant. The network returns a prediction built from disparity estimation, which fills in wrongly predicted regions using a occlusion handling technique. To do so, during training, the network learns to estimate the left-right consistency structural constraint on the pair of stereo input images, to be able to replicate it at test time from one single image. At test time, the approach can generate a left-side and a right-side view from one input image, as well as a depth map and a pixelwise confidence measure in the prediction. The work outperforms visually and metric-wise state-of-the-art approaches on the challenging KITTI dataset, all while reducing by a very significant order of magnitude the required number of parameters (6.5 M). [More here ...] |

|
We have developed a lightweight neural network architecture with an adversarial loss for generating a full light field from one single image. The method is able to estimate disparity maps and automatically identify occluded regions from one single image thanks to a disparity confidence map based on forward-backward consistency checks. The disparity confidence map also controls the use of an adversarial loss for occlusion handling. The approach outperforms reference methods when trained and tested on light field data. Besides, we also designed the method so that it can %to be able to efficiently generate a full light field from one single image, even when trained only on stereo data. This allows us to generalize our approach for view synthesis to more diverse data and semantics. [preprint] [More here ...] |

|
We have developed a learning-based framework for light field view synthesis from a subset of input views. Building upon a light-weight optical flow estimation network to obtain depth maps, our method employs two reconstruction modules in pixel and feature domains respectively. For the pixel-wise reconstruction, occlusions are explicitly handled by a disparity-dependent interpolation filter, whereas inpainting on disoccluded areas is learned by convolutional layers. Due to disparity inconsistencies, the pixel-based reconstruction may lead to blurriness in highly textured areas as well as on object contours. On the contrary, the featurebased reconstruction well performs on high frequencies, making the reconstruction in the two domains complementary. End-to-end learning is finally performed including a fusion module merging pixel and feature-based reconstructions. Experimental results show that our method achieves state-of-the-art performance on both synthetic and realworld datasets, moreover, it is even able to extend light fields’ baseline by extrapolating high quality views without additional training. [preprint], [supplementary] |

|
We have developed a deep residual architecture that can be used both for synthesizing high quality angular views in light fields and temporal frames in classical videos. The proposed framework consists of an optical flow estimator optimized for view synthesis, a trainable feature extractor and a residual convolutional network for pixel and feature-based view reconstruction. Among these modules, the fine-tuning of the optical flow estimator specifically for the view synthesis task yields scene depth or motion information that is well optimized for the targeted problem. In cooperation with the end-to-end trainable encoder, the synthesis block employs both pixel-based and feature-based synthesis with residual connection blocks, and the two synthesized views are fused with the help of a learned soft mask to obtain the final reconstructed view. Experimental results with various datasets show that our method performs favorably against other state-of-the-art (SOTA) methods with a large gain for light field view synthesis. Furthermore, with a little modification, our method can also be used for video frame interpolation, generating high quality frames compared with SOTA interpolation methods. [More here ...] |
|
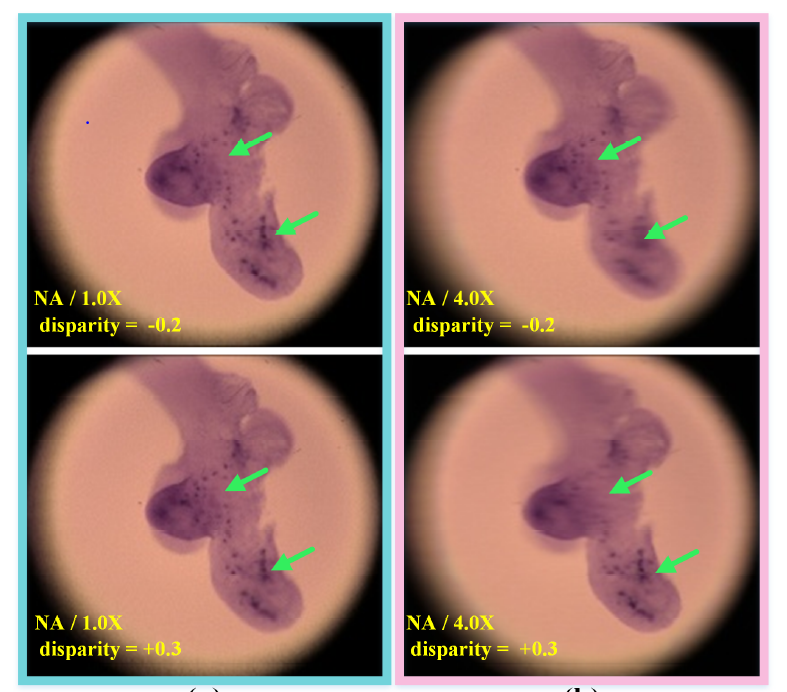
Axial light field resolution refers to the ability to distinguish features at different depths by refocusing. The axial refocusing precision corresponds to the minimum distance in the axial direction between two distinguishable refocusing planes. High refocusing precision can be essential for some light field applications like microscopy. In this paper, we first introduce a refocusing precision model based on a geometrical analysis of the flow of rays within the virtual camera. The model establishes the relationship between the feature distinguishability by refocusing and different camera settings. We then present a learning-based method to extrapolate novel views from axial volumes of sheared epipolar plane images (EPIs). As extended numerical aperture (NA) in classical imaging, the extrapolated light field gives refocused images with a shallower depth of field (DOF), leading to more accurate refocusing results. Most importantly, the proposed approach does not need accurate depth estimation. Experimental results with both synthetic and real light fields show that the method not only works well for light fields with small baselines as those captured by plenoptic cameras (especially for the plenoptic 1.0 cameras), but also applies to light fields with larger baselines. [preprint> |
|
In collaboration with Trinity College Dubli, we have developed a new Light Field representation for efficient Light Field processing and rendering called Fourier Disparity Layers (FDL). The proposed FDL representation samples the Light Field in the depth (or equivalently the disparity) dimension by decomposing the scene as a discrete sum of layers. The layers can be constructed from various types of Light Field inputs including a set of sub-aperture images, a focal stack, or even a combination of both. From our derivations in the Fourier domain, the layers are simply obtained by a regularized least square regression performed independently at each spatial frequency, which is efficiently parallelized in a GPU implementation. Our model is also used to derive a gradient descent based calibration step that estimates the input view positions and an optimal set of disparity values required for the layer construction. Once the layers are known, they can be shifted and filtered to produce different viewpoints of the scene while controlling the focus and simulating a camera aperture of arbitrary shape and size, and used for real time Light Field rendering, view interpolation, extrapolation, and denoising.[More here ...] |

|
We study the problem of low rank approximation of light fields for compression. A homography-based approximation method has been developed which jointly searches for homographies to align the different views of the light field together with the low rank approximation matrices. A coding algorithm relying on this homography-based low rank approximation has then been designed. The two key parameters of the coding algorithm (rank and quantization parameter) are, for a given target bit-rate, predicted with a model learned from input light fields texture and disparity features, using radom trees. The results show the benefit of the joint optimization of the homographies together with the low-rank approximation as well as PSNR-rate performance gains compared with those obtained by directly applying HEVC on the light field views re-structured as a video sequence.[More here ...] |
|
We have addressed the problem of light field dimensionality reduction for compression. We have developed a local low rank approximation method using a parametric disparity model. The local support of the approximation is defined by super-rays. A super-ray can be seen as a set of super-pixels that are coherent across all light field views. A dedicated super-ray construction method has first been designed that constrains the super-pixels forming a given super-ray to be all of the same shape and size, dealing with occlusions. This constraint is needed so that the super-rays can be used as supports of angular dimensionality reduction based on low rank matrix approximation. The light field low rank assumption depends on how much the views are correlated, i.e. on how well they can be aligned by disparity compensation. We first introduced a parametric model describing the local variations of disparity within each super-ray. We then considered two methods for estimating the model parameters. The first method simply fits the model on an input disparity map. We then introduced a disparity estimation method using a low rank prior. This method alternatively searches for the best parameters of the disparity model and of the low rank approximation. We assessed the proposed disparity parametric model, first assuming that the disparity is constant within a super-ray, and second by considering an affine disparity model. We have shown that using the proposed disparity parametric model and estimation algorithm gives an alignment of super-pixels across views that favours the low rank approximation compared with using disparity estimated with classical computer vision methods. The low rank matrix approximation is computed on the disparity compensated super- rays using a singular value decomposition (SVD). A coding algorithm has then been designed for the different components of the proposed disparity-compensated low rank approximation. Experimental results show performance gains, with a rate saving going up to 92.61%, compared with the JPEG Pleno anchor, for real light fields captured by a Lytro Illum camera. The rate saving goes up to 37.72% with synthetic light fields. The approach has also been shown to outperform an HEVC-based light field compression scheme. |
|
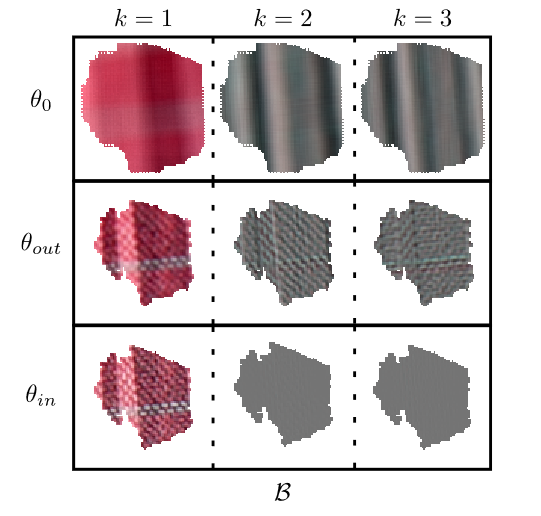
We have addressed the problem of energy compaction of dense 4D light fields by designing geometry-aware local graph-based transforms. Local graphs are constructed on super-rays that can be seen as a grouping of spatially and geometry-dependent angularly correlated pixels. Both non separable and separable transforms are considered. Despite the local support of limited size defined by the super-rays, the Laplacian matrix of the non separable graph remains of highdimension and its diagonalization to compute the transform eigen vectors remains computa-tionally expensive. To solve this problem, we then perform the local spatio-angular transform in a separable manner. We show that when the shape of corresponding super-pixels in the different views is not isometric, the basis functions of the spatial transforms are not coherent, resulting in decreased correlation between spatial transform coefficients. We hence propose a novel transform optimization method that aims at preserving angular correlation even when the shapes of the super-pixels are not isometric. Experimental results show the benefit of theapproach in terms of energy compaction. A coding scheme is also described to assess the rate-distortion perfomances of the proposed transforms and is compared to state of the art encodersnamely HEVC and JPEG Pleno VM 1.1 [More here ...] |
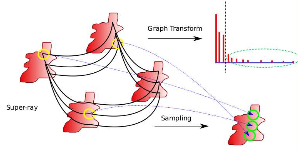
|
Graph-based transforms have been shown to be powerful tools in terms of image energy compaction. However, when the support increases to best capture signal dependencies, the computation of the basis functions becomes rapidly untractable. This problem is in particular compelling for high dimensional imaging data such as light fields. The use of local transforms with limited supports is a way to cope with this computational difficulty. Unfortunately, the locality of the support may not allow us to fully exploit long term signal dependencies present in both the spatial and angular dimensions in the case of light fields. This paper describes sampling and prediction schemes with local graph-based transforms enabling to efficiently compact thesignal energy and exploit dependencies beyond the local graph support. The proposed approach is investigated and is shown to be very efficient in the context of spatio-angular transforms for quasi-lossless compression of light fields.[More here ...] |
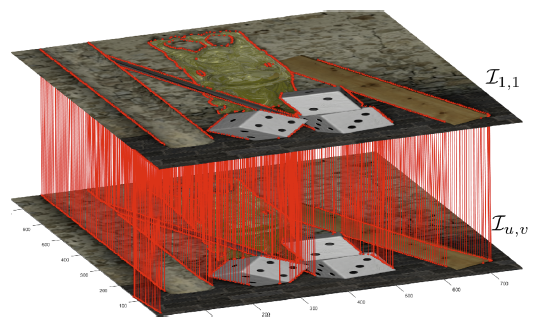
|
We have explored the use of graph-based representations for light fields. The graph connections are derived from the disparity and hold just enough information to synthesize other sub-aperture images from one reference image of the light field. Based on the concept of epipolar segment, the graph connections are sparsified (less important segments are removed) by a rate-distortion optimization. The graph vertices and connections are compressed using HEVC. The graph connections capturing the inter-view dependencies are used as the support of a Graph Fourier Transform used to encode disoccluded pixels. [More here ...] |
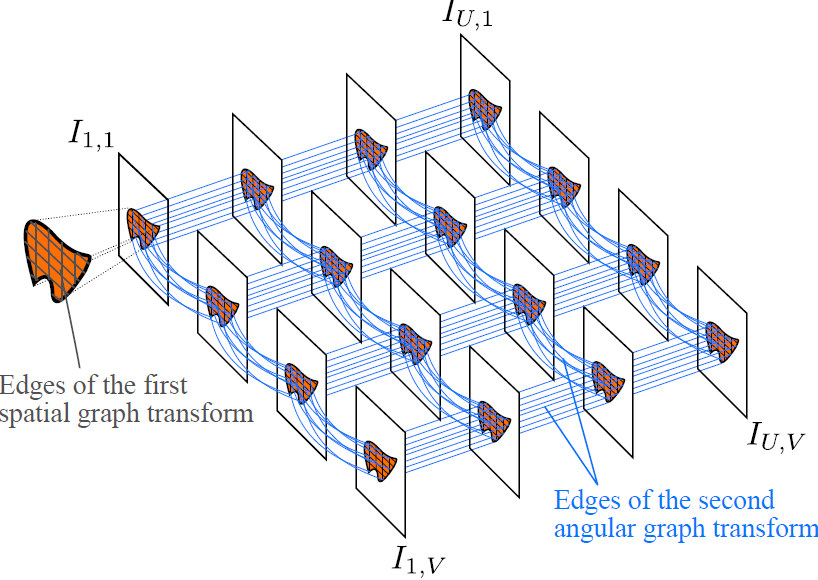
|
We have explored the use of graph-based transforms to capture correlation in light fields. We consider a scheme in which view synthesis is used as a first step to exploit inter-view correlation. Local graph-based transforms (GT) are then considered for energy compaction of the residue signals. The structure of the local graphs is derived from a coherent super-pixel over-segmentation of the different views. The GT is computed and applied in a separable manner with a first spatial unweighted transform followed by an inter-view GT. For the inter-view GT, both unweighted and weighted GT have been considered. The use of separable instead of non separable transforms allows us to limit the complexity inherent to the computation of the basis functions. A dedicated simple coding scheme is then described for the proposed GT based light field decomposition. Experimental results show a significant improvement with our method compared to the CNN view synthesis method and to the HEVC direct coding of the light field views.[More here ...] |
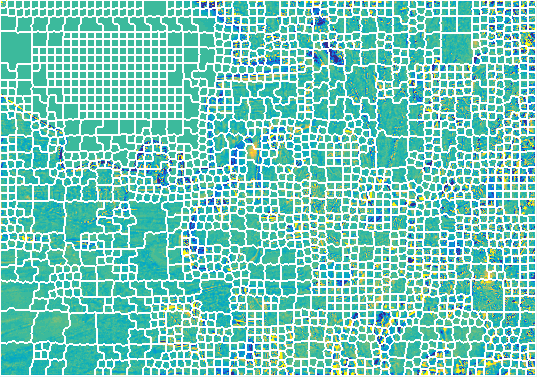
|
We describe a method for constructing super-rays to be used as the support of a 4D shape-adaptive transforms. Super-rays are used to capture inter-view and spatial redundancy in light fields. Here, we consider a scheme in which a first step of view synthesis based on CNN is used to remove inter-view correlation. The super-ray based transforms are then applied on prediction residues. To ensure that the super-ray segmentation is highly correlated with the residues to be encoded, the super-rays are computed on synthesized residues and optimized in a rate-distortion sense. Experimental results show that the proposed coding scheme outperforms HEVC-based schemes at low bitrate.[More here ...] |
|
We have developed a compression method for light fields based on the Fourier Disparity Layer representation. This light field representation consists in a set of layers that can be efficiently constructed in the Fourier domain from a sparse set of views, and then used to reconstruct intermediate viewpoints without requiring a disparity map. In the proposed compression scheme, a subset of light field views is encoded first and used to construct a Fourier Disparity Layer model from which a second subset of views is predicted. After encoding and decoding the residual of those predicted views, a larger set of decoded views is available, allowing us to refine the layer model in order to predict the next views with increased accuracy. The procedure is repeated until the complete set of light field views is encoded. [More here ...] |
|
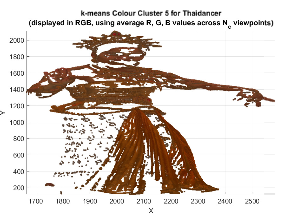
The recently introduced plenoptic point cloud representation marries a 3D point cloud with a light field. Instead of each point being associated with a single colour value, there can be multiple values to represent the colour at that point as perceived from different viewpoints. This representation was introduced together with acompression technique for the multi-view colour vectors, which is an extension of the RAHT method for point cloud attribute coding.In the current paper, we demonstrate that the best-proposed RAHT extension, RAHT-KLT, can be improved by performing a prior sub-division of the plenoptic point cloud into clusters based on similar colour values, followed by a separation of each cluster into specular and diffuse components, and coding each component separately with RAHT-KLT. Our proposed improvements are shown to achieve better rate-distortion results than the original RAHT-KLT method.[preprint] |
|
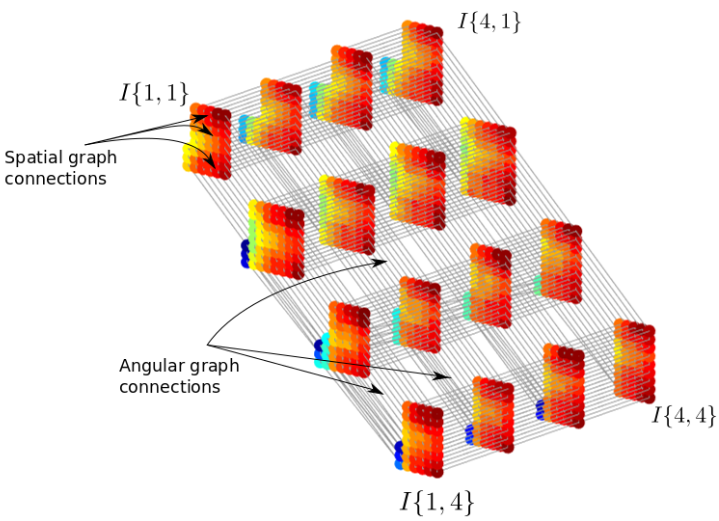
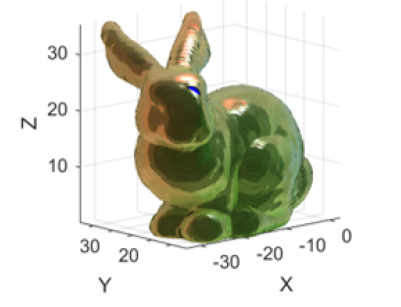
We have introduced a novel 6-D representation of plenoptic point clouds, enabling joint, non-separable transform coding of plenoptic signals defined along both spatial and angular (viewpoint) dimensions. This 6-D representation, which is built in a global coordinate system, can be used in both multi-camera studio capture and video fly-by capture scenarios, with various viewpoint (camera) arrangements and densities. We show that both the Region-Adaptive Hierarchical Transform (RAHT) and the Graph Fourier Transform (GFT) can be extended to the proposed 6-D representation to enable the non-separable transform coding. Our method is applicable to plenoptic data with either dense or sparse sets of viewpoints, and to complete or incomplete plenoptic data, while the stateof- the-art RAHT-KLT method, which is separable in spatial and angular dimensions, is applicable only to complete plenoptic data. The “complete” plenoptic data refers to data that has, for each spatial point, one colour for every viewpoint (ignoring any occlusions), while “incomplete” data has colours only for the visible surface points at each viewpoint. We demonstrate that the proposed 6-D RAHT and 6-D GFT compression methods are able to outperform the state-of-the-art RAHT-KLT method on 3- D objects with various levels of surface specularity, and captured with different camera arrangements and different degrees of viewpoint sparsity. |
|
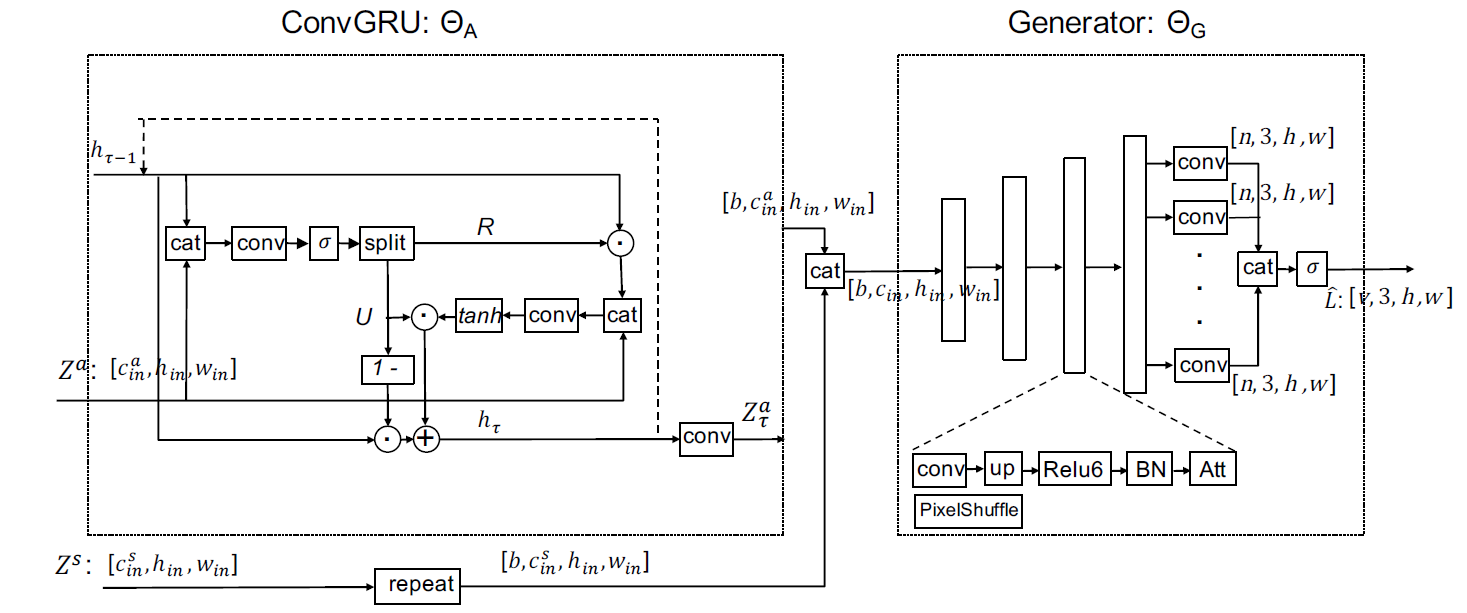
Deep generative models have proven to be effective priors for solving a variety of image processing problems. However, the learning of realistic image priors, based on a large number of parameters, requires a large amount of training data. It has been shown recently, with the so-called deep image prior (DIP), that randomly initialized neural networks can act as good image priors without learning. In this paper, we propose a deep generative model for light fields, which is compact and which does not require any training data other than the light field itself. To show the potential of the proposed generative model, we develop a complete light field compression scheme with quantizationaware learning and entropy coding of the quantized weights. Experimental results show that the proposed method outperforms state-of-the-art light field compression methods as well as recent deep video compression methods in terms of both PSNR and MS-SSIM metrics. |

|
We have developed an novel method for propagating the inpainting of the central view of a light field to all the other views in order to inpaint all views in a consistent manner. After generating a set of warped versions of the inpainted central view with random homographies, both the original light field views and the warped ones are vectorized and concatenated into a matrix. Because of the redundancy between the views, the matrix satisfies a low rank assumption enabling us to fill the region to inpaint with low rank matrix completion. A new matrix completion algorithm, better suited to the inpainting application than existing methods, has also been developed. Unlike most existing light field inpainting algorithms, our method does not require any depth prior. Another interesting feature of the low rank approach is its ability to cope with color and illumination variations between the input views of the light field. .[More here ...] |

|
This paper presents a novel approach for light field editing. The problem of propagating an edit from a single view to the remaining light field is solved by a structure tensor driven diffusion on the epipolar plane images. The proposed method is shown to be useful for two applications: light field inpainting and recolorization. While the light field recolorization is obtained with a straightforward diffusion, the inpainting application is particularly challenging, as the structure tensors accounting for disparities are unknown under the occluding mask. We address this issue with a disparity inpainting by means of an interpolation constrained by superpixel boundaries. Results on synthetic and real light field images demonstrate the effectiveness of the proposed method. .[More here ...] |
|
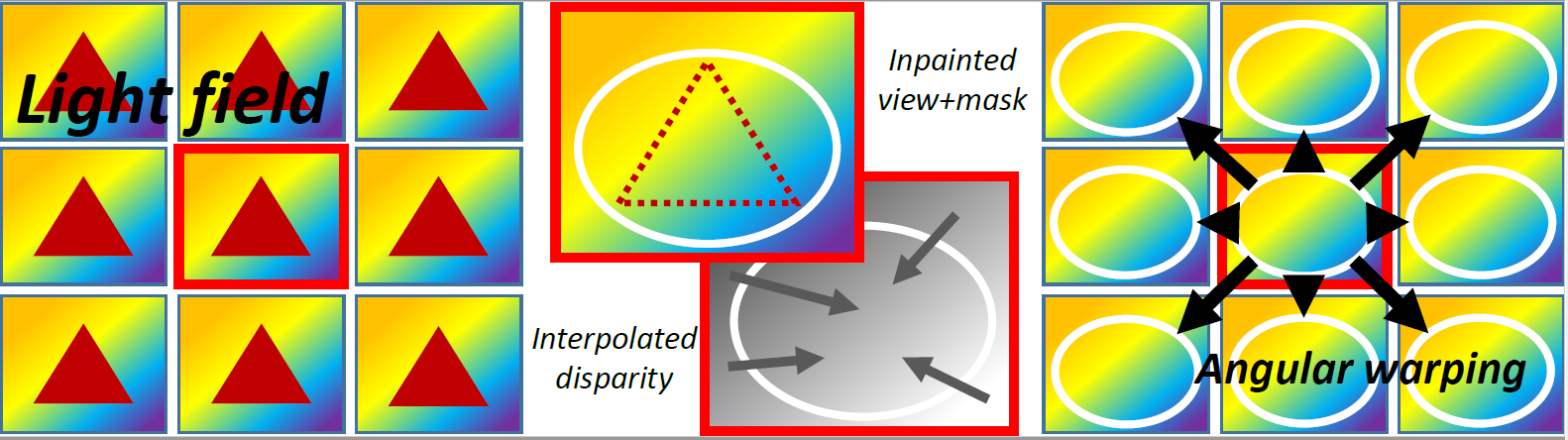
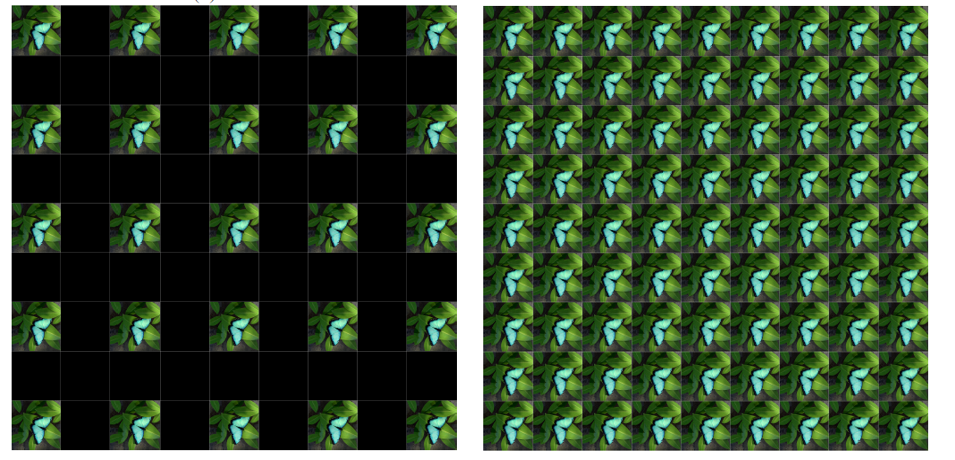
This paper describes a method for fast and efficient inpainting of light fields. We first revisit disparity estimation based on smoothed structure tensors and analyze typical artefacts with their impact for the inpainting problem. We then propose an approach which is computationally fast while giving more coherent disparity in the masked region. This disparity is then used for propagating, by angular warping, the inpainted texture of one view to the entire light field. Performed experiments show the ability of our approach to yield appealing results while running considerably faster.[More here ...] |
|
We have considered the problem of vector valued regularization of light fields based on PDEs. We propose a regularization method operating in the 4D ray space that does not require prior estimation of disparity maps. The method performs a PDE-based anisotropic diffusion along directions defined by local structures in the 4D ray space. We analyze light field regularization in the 4D ray space using the proposed 4D anisotropic diffusion framework, and illustrate its effect for several light field processing applications: denoising, angular and spatial interpolation, regularization for enhancing disparity estimation as well as inpainting. [More here ...] |

|
We have developed a novel light field denoising algorithm using a vector-valued regularization operating in the 4D ray space. The method performs a PDE-based anisotropic diffusion along directions defined by local structures in the 4D ray space. It does not require prior estimation of disparity maps. The local structures in the 4D light field are extracted using a 4D tensor structure. Experimental results show that the proposed denoising algorithm performs well compared to state of the art methods while keeping tractable complexity.[More here ...] |
|
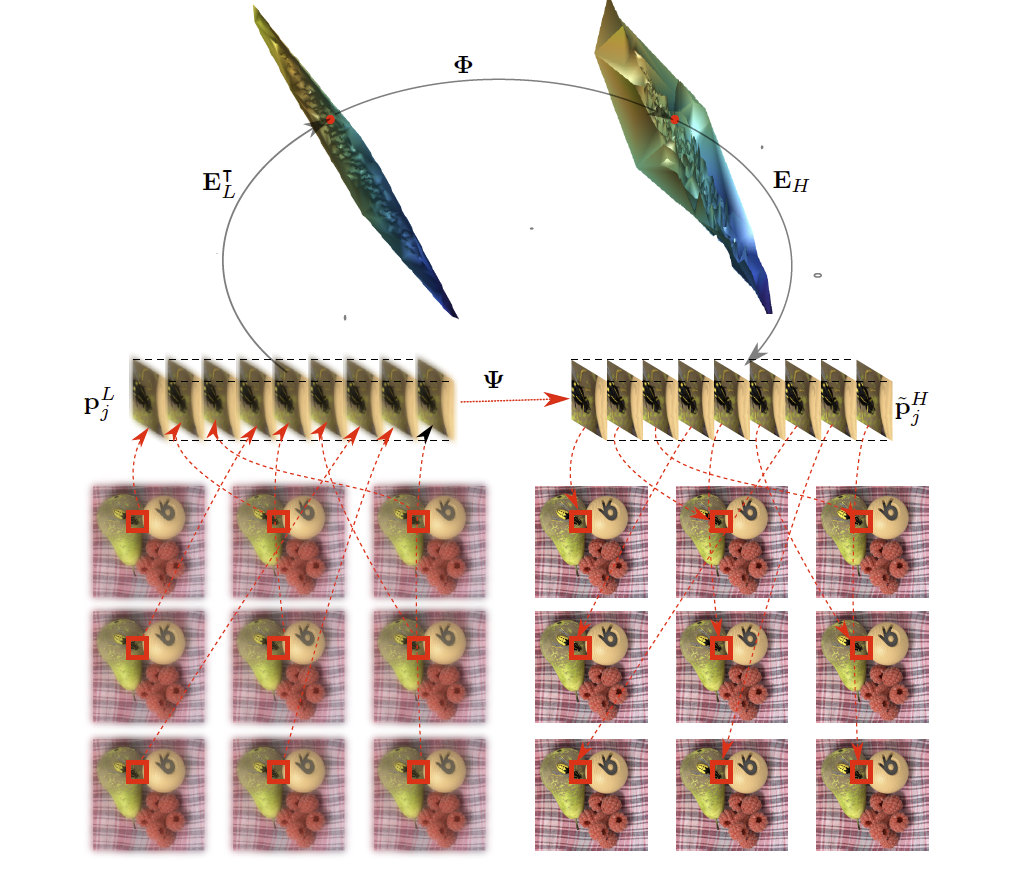
We have developed an example-based super-resolution algorithm for light fields, which allows the increase of the spatial resolution of the different views in a consistent manner across all sub-aperture images of the light field. The algorithm learns linear projections between subspaces of reduced dimension in which reside patch-volumes extracted from the light field. The method is extended to cope with angular super-resolution, where 2D patches of intermediate sub-aperture images are approximated from neighbouring subaperture images using multivariate ridge regression. Experimental results show significant quality improvement when compared to state-of-the-art single-image super-resolution methods applied on each view separately, as well as when compared to a recent light field super-resolution technique based on deep learning.[More here ...] |
|
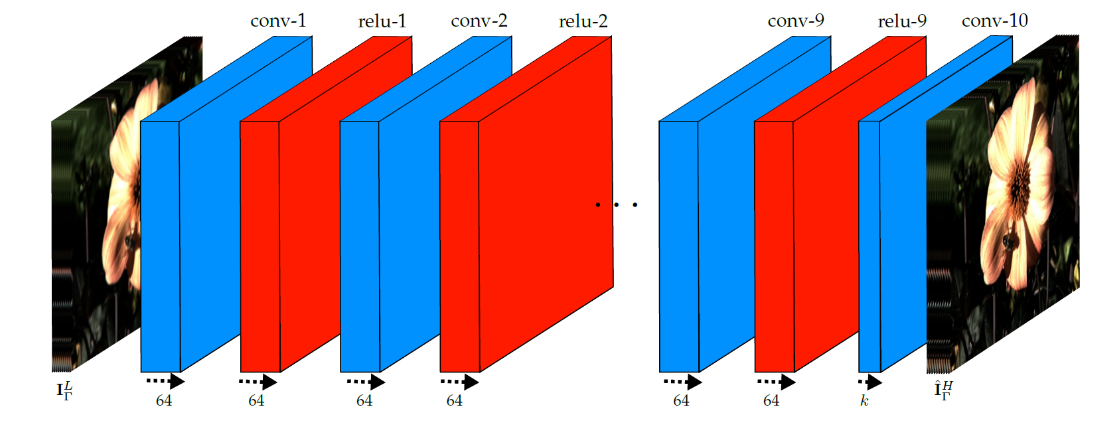
This paper describes a learning-based spatial light field super-resolution method that allows the restoration of the entire light field with consistency across all sub-aperture images. The algorithm first uses optical flow to align the light field and then reduces its angular dimension using low-rank approximation. We then consider the linearly independent columns of the resulting low-rank model as an embedding, which is restored using a deep convolutional neural network (DCNN). The super-resolved embedding is then used to reconstruct the remaining sub-aperture images. The original disparities are restored using inverse warping where missing pixels are approximated using a novel light field inpainting algorithm. Experimental results show that the proposed method outperforms existing light field super-resolution algorithms, including using convolutional networks. |
|
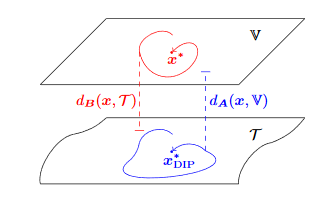
The Deep Image Prior has been recently introduced to solve inverse problems in image processing with no need for training data other than the image itself. However, the original training algorithm of the Deep Image Prior constrains the reconstructed image to be on a manifold described by a con-volutional neural network. For some problems, this neglects prior knowledge and can render certain regularizers ineffective. This work proposes an alternative approach that relaxes this constraint and fully exploits all prior knowledge. We evaluate our algorithm on the problem of reconstructing a high-resolution image from a downsampled version and observe a significant improvement over the original Deep Image Prior algorithm.[preprint] |
|
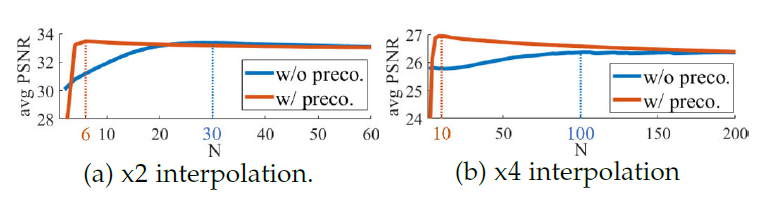
Plug-and-Play optimization recently emerged as a powerful technique for solving inverse problems by plugging a denoiser into a classical optimization algorithm. The denoiser accounts for the regularization and therefore implicitly determines the prior knowledge on the data, hence replacing typical handcrafted priors. We have extended the concept of plug-and-play optimization to use denoisers that can be parameterized for non-constant noise variance. In that aim, we have introduced a preconditioning of the ADMM algorithm, which mathematically justifies the use of such an adjustable denoiser. We additionally proposed a procedure for training a convolutional neural network for high quality non-blind image denoising that also allows for pixel-wise control of the noise standard deviation. We have shown that our pixel-wise adjustable denoiser, along with a suitable preconditioning strategy, can further improve the plug-and-play ADMM approach for several applications, including image completion, interpolation, demosaicing and Poisson denoising [preprint] |