Rate-Distortion Optimized Super-Ray Merging for Light Field Compression
Abstract
In this paper, we focus on the problem of compressing dense light fields (LF)
which represent very large volumes of highly redundant data.
In our scheme, view synthesis based on convolutional neural networks
(CNN) is used as a first prediction step to exploit inter-view correlation.
Super-rays are then constructed to capture the inter-view and spatial redundancy
remaining in the prediction residues.
To ensure that the super-ray segmentation is highly correlated with the residues to be encoded,
the super-rays are computed on synthesized residues
(the difference between the four transmitted corner views and their corresponding synthesized views),
instead of the synthesized views.
Neighboring super-rays are merged into a larger super-ray according to a rate-distortion cost.
A 4D shape adaptive discrete cosine transform (SA-DCT) is applied per super-ray on
the prediction residues in both the spatial and angular dimensions.
A traditional coding scheme consisting of quantization and entropy coding is then used for encoding
the transformed coefficients.
Experimental results show that the proposed coding scheme outperforms HEVC-based schemes at low bitrate.
.
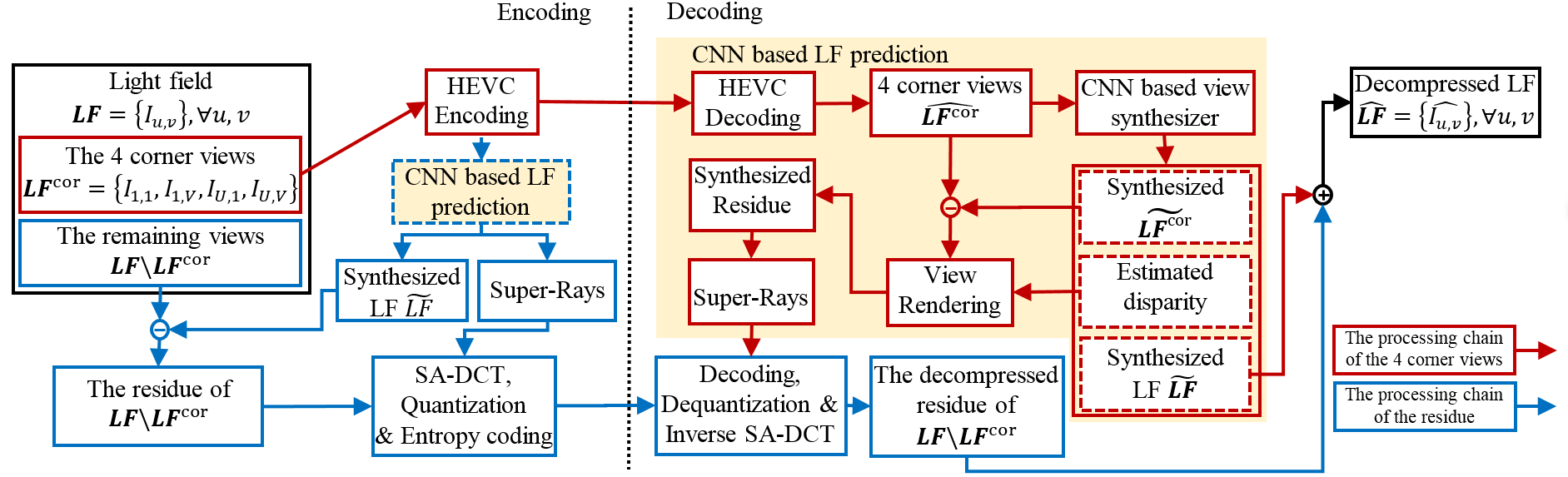
The Proposed Coding Scheme
Four views of LF at corners are encoded using HEVC-Inter
and used to synthesize the whole light field with the CNN based synthesis method [Kalantari2016]
(red arrows in the following figure).
To improve the quality of the synthesized light field,
the residuals between the synthesized and original views are
encoded by applying local super-ray based shape adaptive
DCT (SA-DCT), see the blue arrows in the following figure.
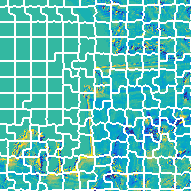
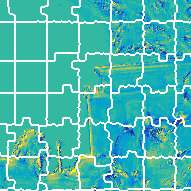
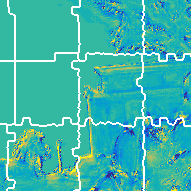
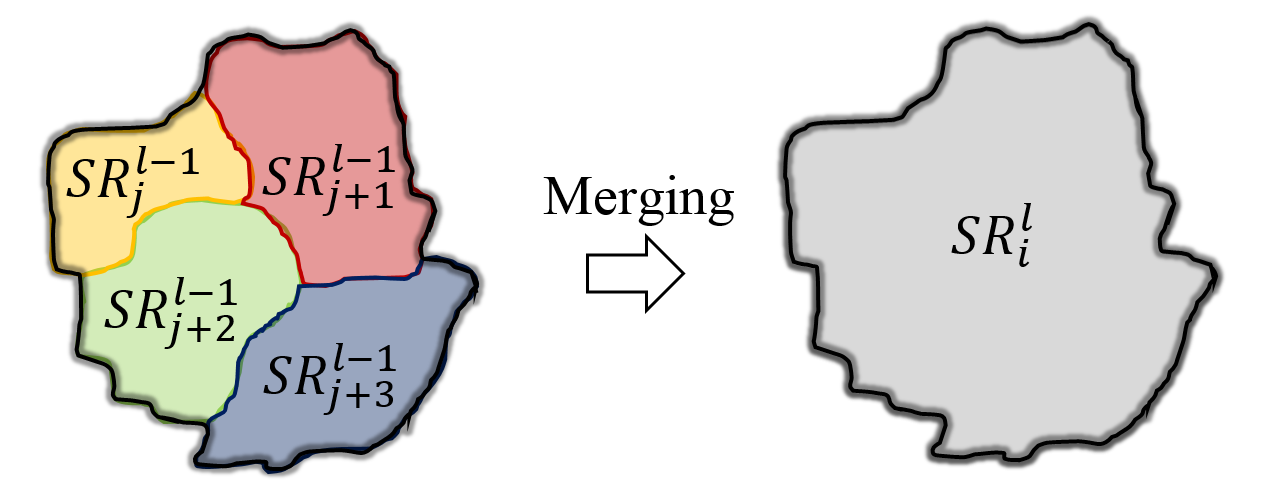
Rate-Distortion Optimized Super-Ray Merging
In order to increase compression performances, we improve
the super-ray segmentation with a rate-distortion optimized
super-ray merging. Four initial segmentations are performed
using different initial numbers of clusters leading to different
super-ray sizes, see the following figure.
The resulting segmentations are referred to as layers.
The merging results are initialized by the super-rays layer 0 and the merging starts from layer 1 to
layer 3.
At each time, we only consider one super-ray at layer l,
which consists of several super-rays layer l-1, see the following figure.
The merging will be done, if the rate-distortion cost reduces after merging.
Datasets
We test our coding scheme on four real LF with 8×8
subaperture images of size (X = 536, Y = 376) from the dataset
used in [Kalantari2016], called Flower1, Rock, Flower2 and Cars.
Results
Energy Compaction
We first evaluate the effectiveness of our 4D segmentation, by analyzing the compaction of the energy after transformation.
Therefore, 4D SA-DCT is applied on:
- Super-pixels used in [Rizkallah2018] (computed on synthesized color without disparity compensation or merging);
- Super-rays computed on synthesized residues without disparity compensation or merging;
- Super-rays computed on synthesized residues with disparity compensation but without merging;
- Super-rays computed on synthesized residues with disparity compensation and merging.
The following figure shows the percentage of energy carried by a given percentage of coefficients obtained by SA-DCT on these segmentations.
The blue curve is the baseline method [Rizkallah2018].
The red curves show the impact of using the synthesized residues to compute the segmentation.
However, due the error in the synthesized residue, the improvement is limited.
The Yellow curve shows the impact of using the disparity information, while the purple curve measures the effect of the merging.
Thanks to the merging operation which compensates the errors in the super-ray segmentation,
the proposed contributions bring a significant increase in terms of energy compaction
(~10%) with respect to a direct use of a super-pixel segmentation per view [Rizkallah2018].

|
|

|
Rate-PSNR results
The final rate-distortion performance of the proposed scheme is evaluated in comparison with three baseline methods:
- HEVC-lozenge [Rizkallah2016],
the whole LF is considered as a video and compressed by HEVC with a lozenge sequence;
- CNN+HEVC [Rizkallah2016],
the same CNN based view synthesis is applied here, while the residues are compressed by HEVC;
- CNN+SA-DCT (no merging, no disparity) [Rizkallah2018],
our previous coding scheme presented in [Rizkallah2018]
using the same CNN based view synthesis,
however, there is no disparity compensation or super-merging strategy.
Note that the coding methods using CNN based prediction are performed with best pairs of parameters
(Q, QP) where Q is the quality parameter used to compress the residues and QP is used in the
HEVC inter-coding of the four corners.
The obtained rate-distortion curves are shown in the following figures.
The proposed CNN+SA-DCT coding scheme yields better or comparable rate-PSNR performance at low bitrate
than HEVC based reference methods.
The improvement of the proposed CNN+SA-DCT compared with the baseline method in [Rizkallah2018]
indicates the effectiveness of super-ray merging.
It allows the proposed coding scheme to capture more information with fewer bits (at low bitrate),
compared with HEVC based encoders.
The average rate-PSNR gain of our coding scheme is ~1.0 (bjontegaard metric) compared with CNN+HEVC [Rizkallah2016]
and ~0.2 compared with HEVC-lozenge [Rizkallah2016] at low bitrate (<0.04 bpp corresponding to a PSNR quality up to 35 dB).
However, at bitrates higher than 0.04 bpp, the HEVC based encoders (HEVC lozenge and CNN+HEVC) generally outperform the proposed coding scheme at high bitrates.
This is due to the fact that the proposed scheme does not have very complex and high quality prediction strategies
in residue coding which is useful at high bitrate.
Reference
| [Kalantari2016] |
N. K. Kalantari, T.-C. Wang, and R. Ramamoorthi, “Learning-based
view synthesis for light field cameras,” ACM Transactions on Graphics
(TOG), vol. 35, no. 6, p. 193, 2016. |
|
|
|
|
|
|
| [Rizkallah2016] |
M. Rizkallah, T. Maugey, C. Yaacoub, and C. Guillemot, “Impact of
light field compression on focus stack and extended focus images,”
in Signal Processing Conference (EUSIPCO), 2016 24th European.
IEEE, 2016, pp. 898–902. |
|
|
|
|
|
|
| [Rizkallah2018] |
M. Rizkallah, X. Su, T. Maugey, and C. Guillemot, “Graph-based
Transforms for Predictive Light Field Compression based on SuperPixels,”
in IEEE International Conf. on Acoustics, Speech and Signal
Processing (ICASSP), 2018. |