Light Field Compression with Homography-based Low Rank Approximation
 |
X. Jiang, M. Le Pendu, R. Farrugia, C. Guillemot,
"Light Field Compression with Homography-based Low Rank Approximation", IEEE Journal of Selected Topics in Signal Processing (J-STSP), vol. 11, No. 7, pp. 1132-1145, Oct. 2017.(pdf) |
Abstract
Datasets
In this work, we consider real light fields captured by plenoptic cameras using an array of micro-lenses, coming from different sources: 1/- INRIA dataset which contains LFs captured either by a first generation Lytro camera (11 × 11 views of 379 × 379 pixels) and a second generation Lytro Illum camera (15 × 15 views of 625 × 434 pixels); 2/- the ICME 2016 Grand Challenge dataset containing 12 Lytro Illum LFs, and we take 13 × 13 central views as defined by the challenge testing conditions.
The complete INRIA dataset can be accessed [ here ...]. It contains 63 LFs captured by Lytro first generation camera and 43 LFs captured by Lytro Illum camera). 4 Lytro 1G LFs ("TotoroWaterfall", "Beers", "Flower" and "TapeMeasure") and 4 Lytro Illum LFs ("Fruits", "Bench", "BouquetFlower1" and "Toys") are used for testing in this paper. The rest of the LFs are used for training the Random Forest based parameter prediction model (c.f. Section "Model-based coding parameters prediction"). We only consider the 9 × 9 central sub-aperture images in order to alleviate the strong vignetting and distortion problems on the views at the periphery of the light field which comparatively more several impacts the performance of the HEVC-based reference schemes. Note that there are still variations of light intensity, but to a lesser extent, in the truncated light fields.
Lytro LFs are decoded by the Matlab Light Field Toolbox v0.4.
Homography-based low rank approximation
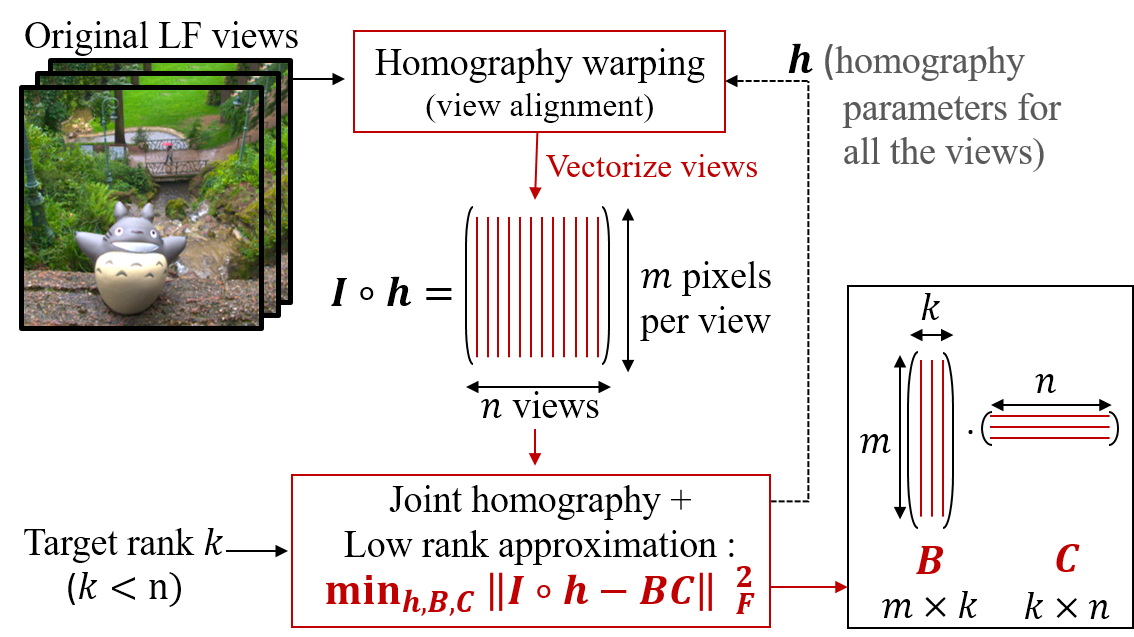
Depth-based multiple homographies
TotoroWaterfalll: separation into 2 depth planes
 |
 |
 |
Compression details
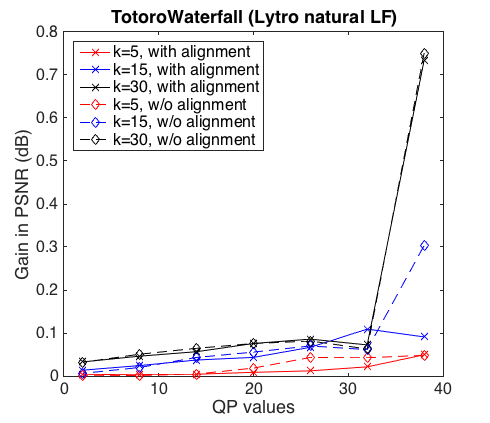
The following figure shows the first 3 columns of B when HLRA is applied for the LF "TotoroWaterfall" with rank k = 5 and 1 homography per image. The first column represents low frequency information, whereas the others contain data with high frequency. One can observe that by using homographies to align sub-aperture views, the average image in the first column becomes sharper, and there is less high frequency information remaining in the following columns.
Columns of matrix B without alignment.
 |
Columns of matrix B with alignment: k = 5, q = 1.
|
 |
Besides the matrix B, additional elements need to be transmitted. The coefficients of the matrix C are encoded using a scalar quantization on 16 bits and Huffman coding. The 8 × n × q homography parameters, with q the number of depth planes per view, are encoded the same way. In the case where multiple homograhies are applied, the depth map is encoded using HEVC intra coding with QP = 32.
Model-based coding parameters prediction
Problem
For a given target bit-rate and a given input light field, the PSNR performance of the compression scheme depends on two key parameters: the rank k of the approximation and the HEVC quantization parameter (QP). The (k, QP) prediction task can be considered as a problem of Multi-output classification (MOC).
Training and Test LFs
c.f. Section "Datasets".
Input Feature space
- Disparity indicators of original light field:
- proportion of singular values of the matrix I which contain at least 95% of the energy of I;
- decay rate of singular values of the matrix I which is defined as the ratio between the first and the second singular value.
- Disparity indicators of aligned light field: same indicators as above computed on the aligned LF.
- Texture indicators: same indicators as above computed on the matrix in which each column is a vectorized version of each 8 × 8 block of the central view.
- Bitrate of the encoded light field for a certain pair (k, QP)
- Target bitrate
Prediction model
We use Random Forest as classifier. For MOC problems, a classical way is to predict separately each label with a different classifier by assuming that these labels are independent. In our case, however, k and QP are strongly correlated. In order to improve the MOC performance, we model the label dependencies by a competitive Classifier Chain (CC). In such a scheme, the values of k and QP are at first separately predicted by two independent Random Forests. We then choose the prediction (k or QP) for which the classifier gets a higher probability and add it into the new feature space. A third Random Forest is then employed to predict the other label with the augmented feature space.
Results
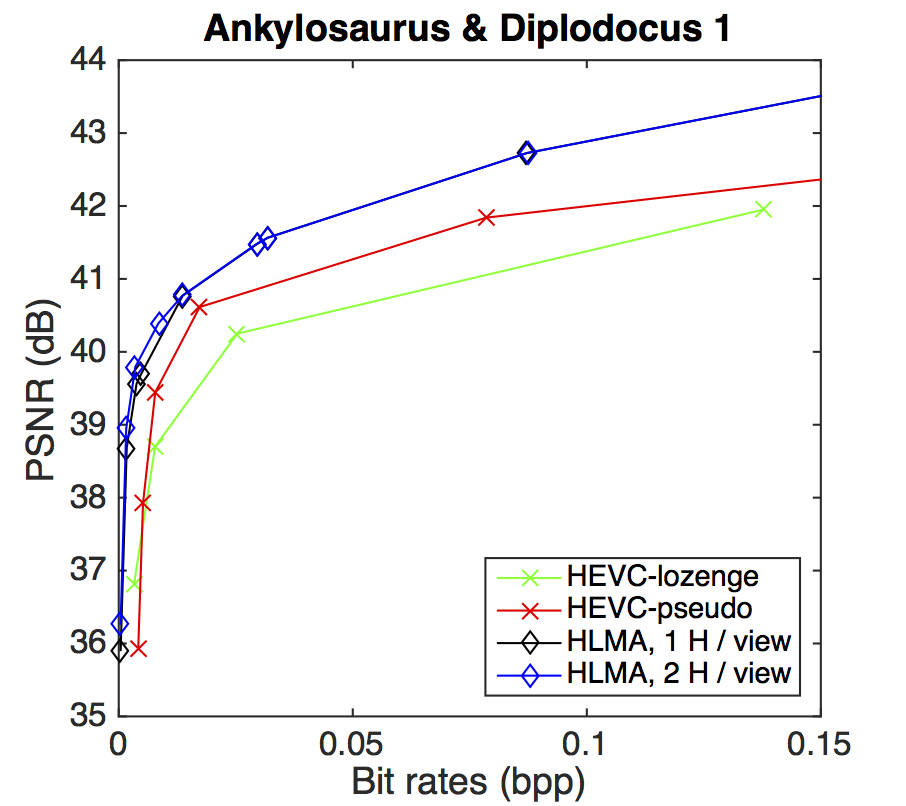
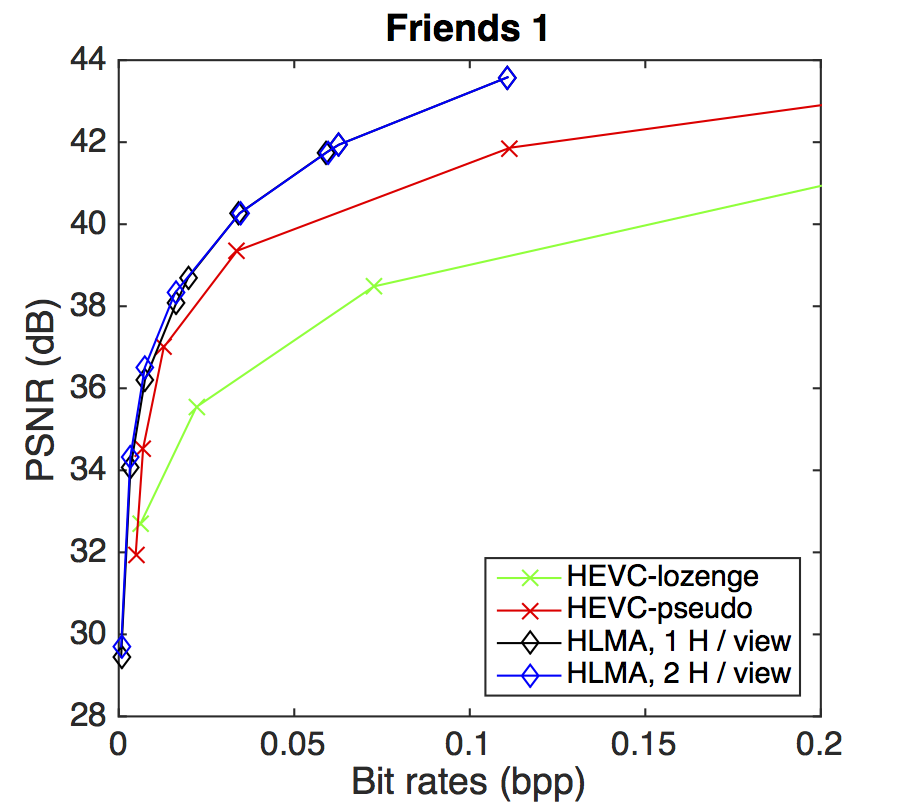
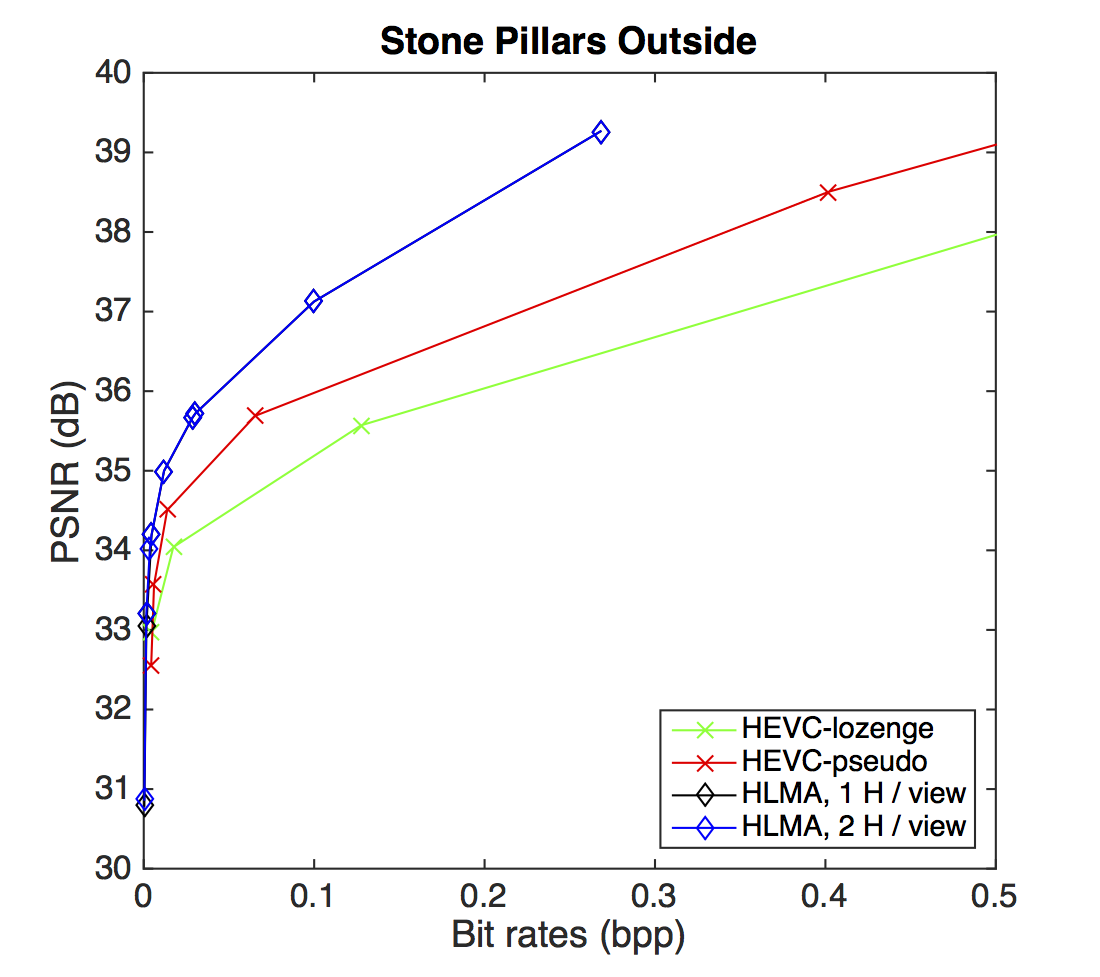
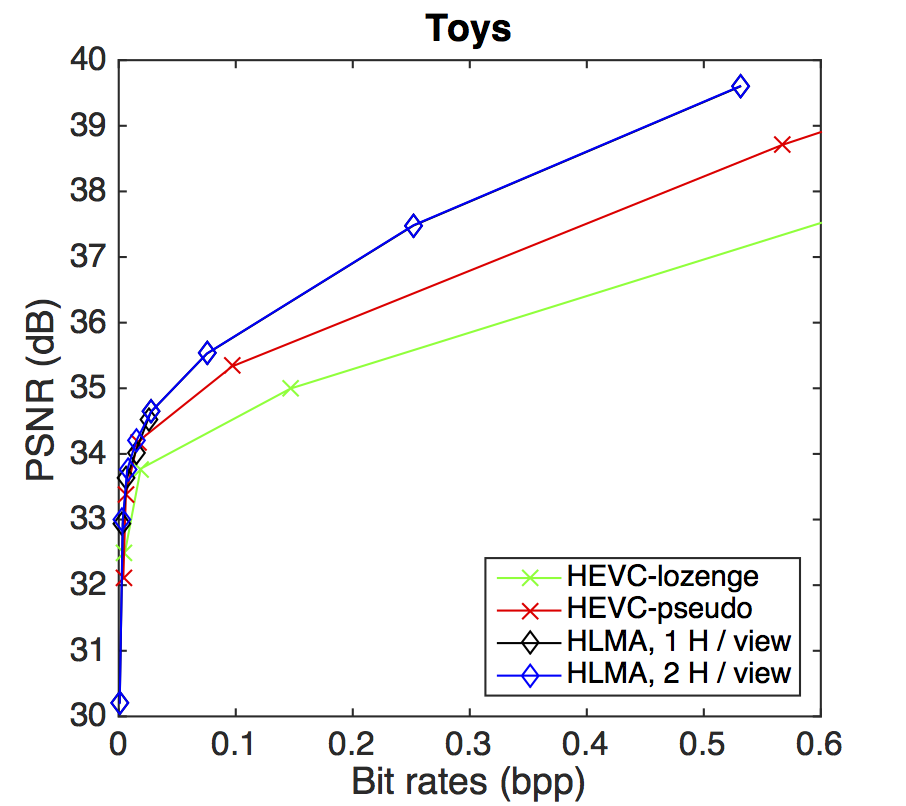
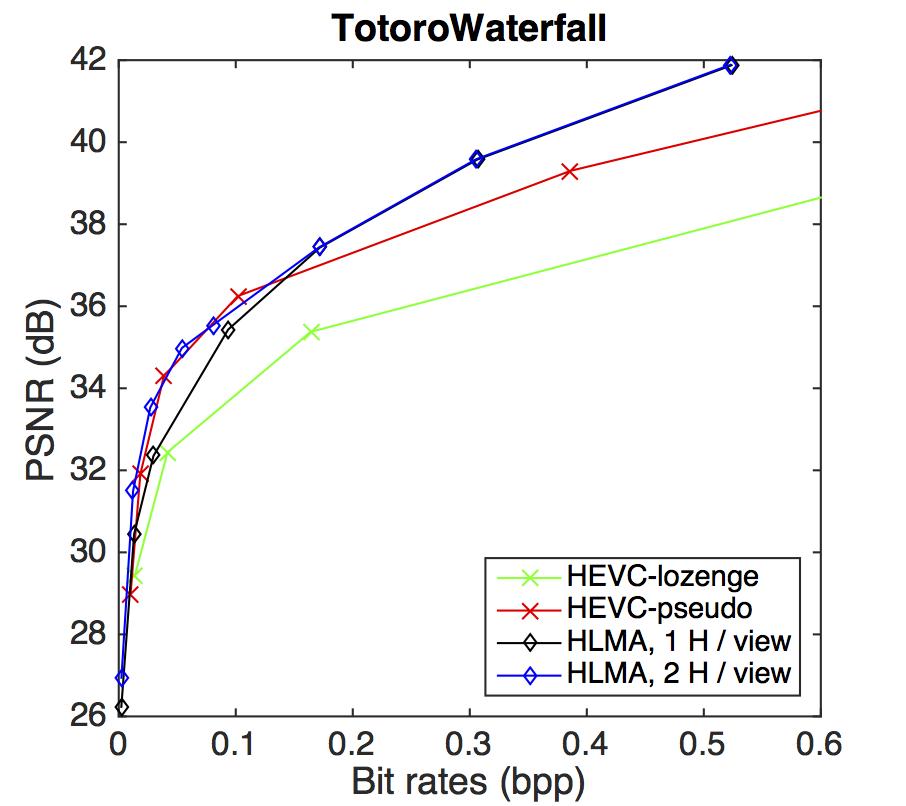
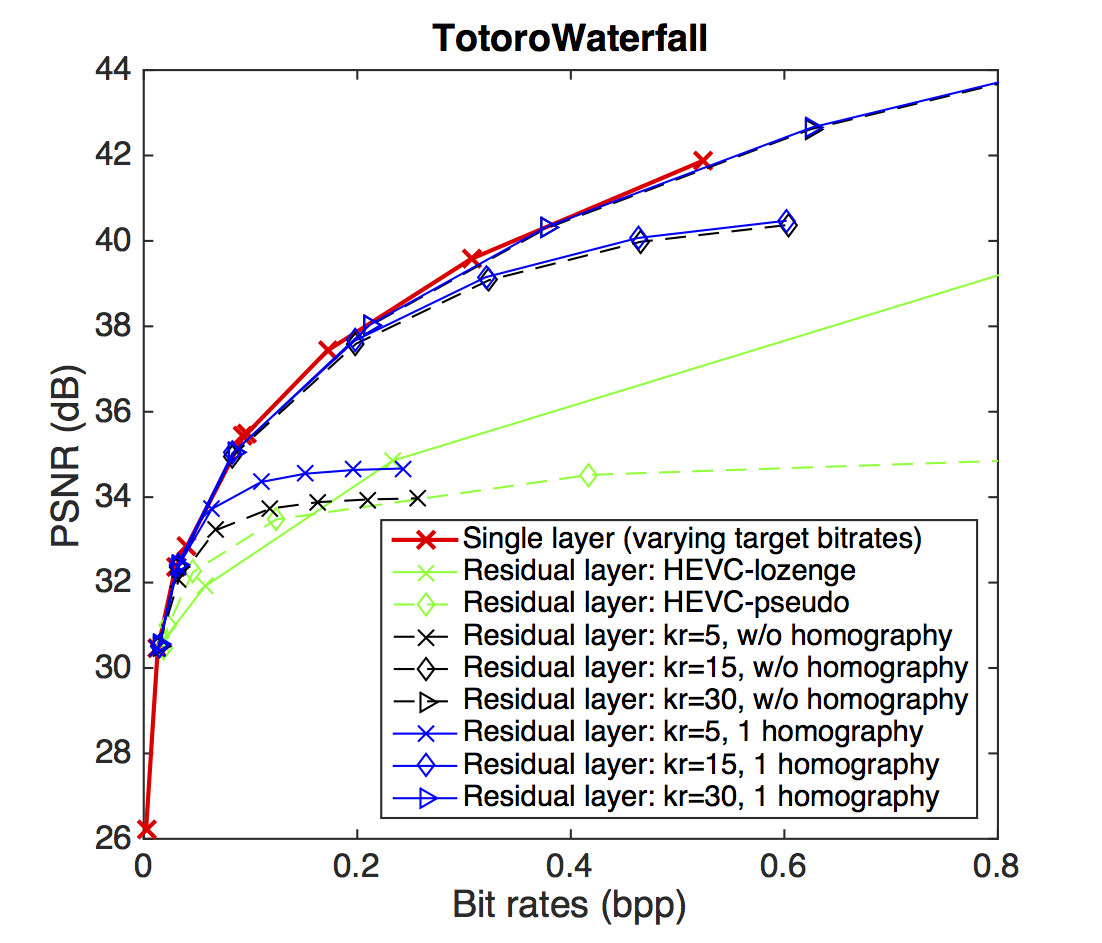
PSNR-rate performance
 |
 |
 |
 |
 |
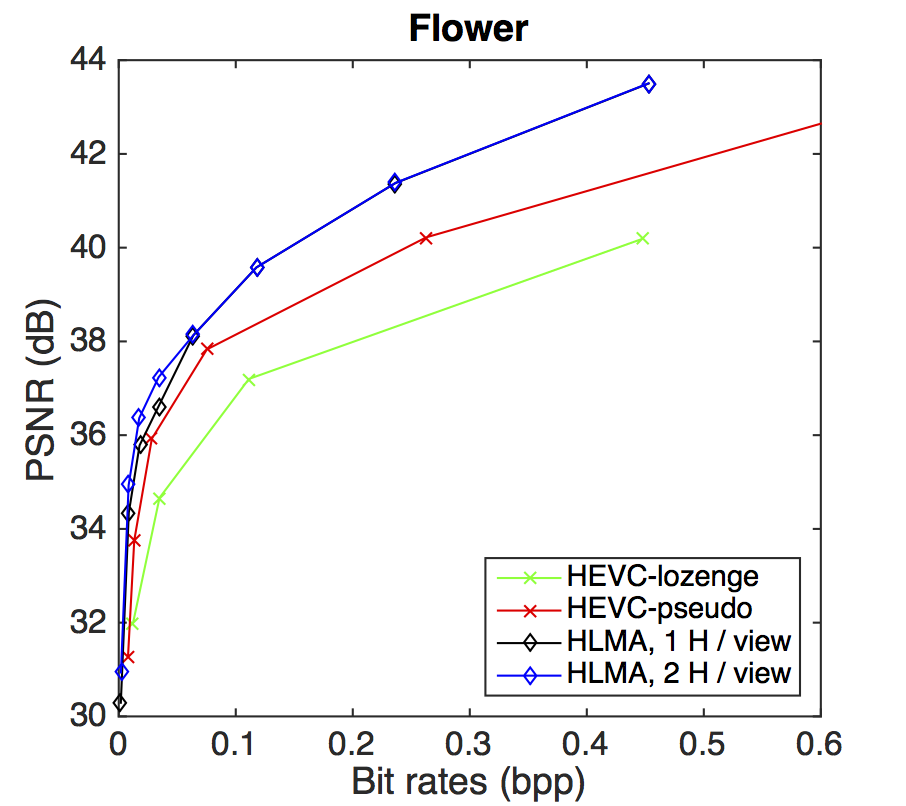 |
BD-PSNR gains with respect to HEVC-lozenge scheme. The gains are shown for the HEVC-pseudo and for our HLRA scheme with one or two homographies per view.
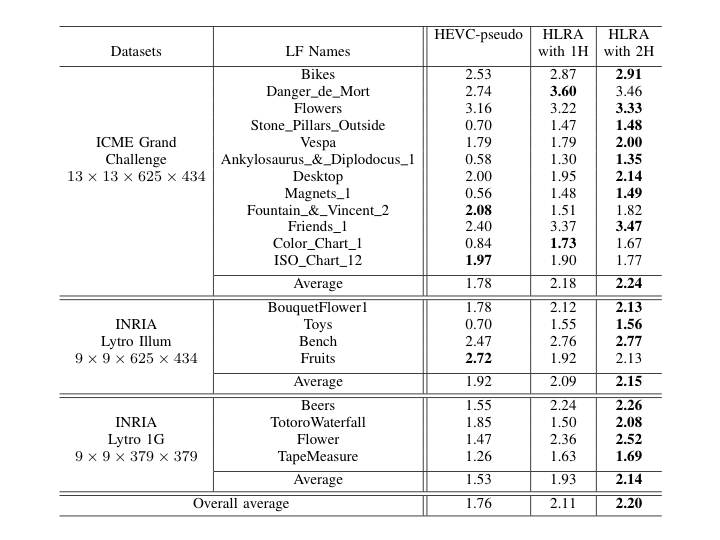 |
Run Times
Complexity comparison. The results are averaged over the test light fields in different dataset. The consumed time is measured at QP=20 both for HLRA and HEVC-pseudo.
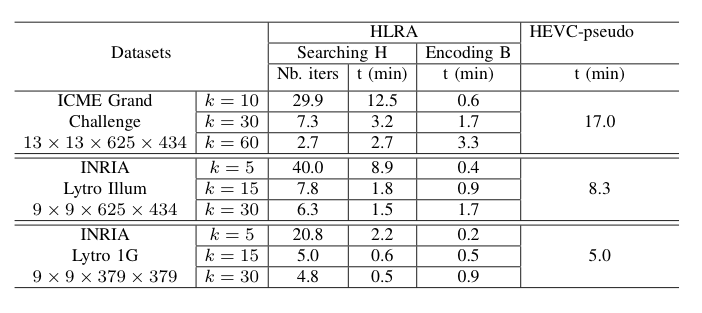 |
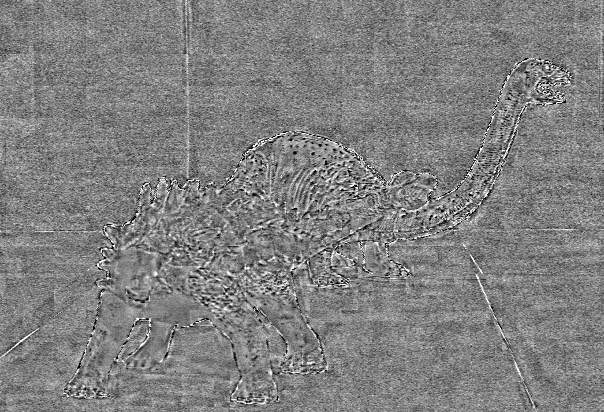
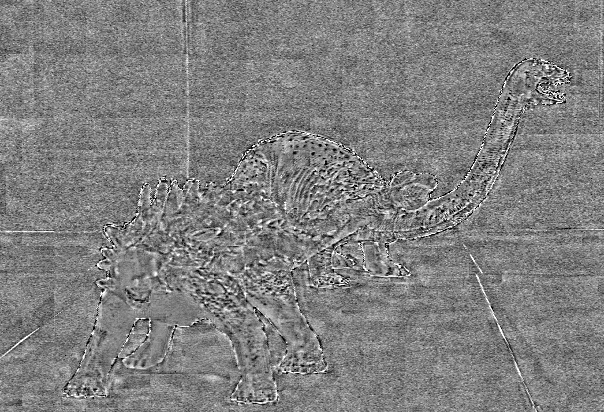
Approximation error
| Original center view | HEVC-lozenge | HEVC-pseudo | HLRA |
 |
 |
 |
 |
| Ankylosaurus Diplodocus 1 | PSNR=38.70 dB, bitrate=7.8 × 10-3 bpp | PSNR=37.92 dB, bitrate=5.2 × 10-3 bpp | PSNR=39.79 dB, bitrate=3.5 × 10-3 bpp |
 |
 |
 |
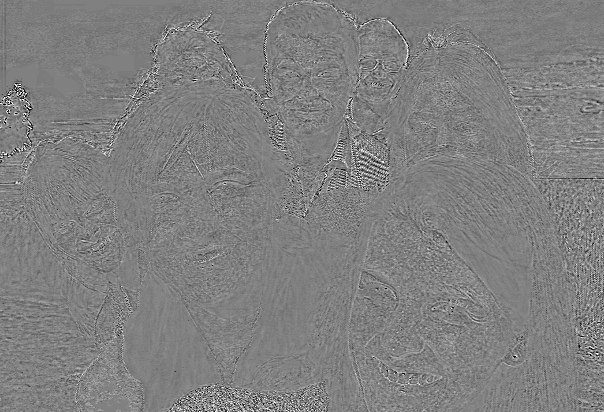 |
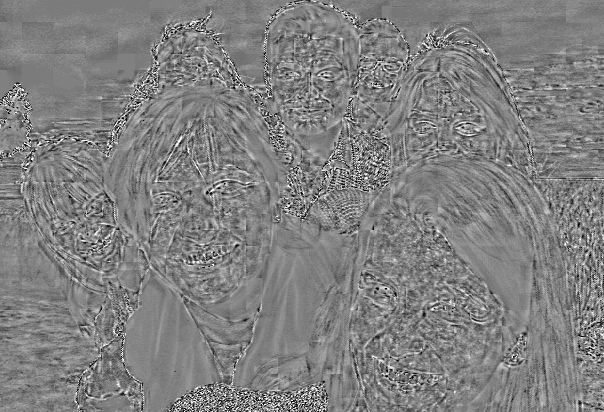
| Friends 1 | PSNR=32.68 dB, bitrate=6.1 × 10-3 bpp | PSNR=34.54 dB, bitrate=6.9 × 10-3 bpp | PSNR=36.50 dB, bitrate=7.4 × 10-3 bpp |
 |
 |
 |
 |
| Stone Pillars Outside | PSNR=34.04 dB, bitrate=1.7 × 10-2 bpp | PSNR=34.54 dB, bitrate=1.5 × 10-2 bpp | PSNR=36.50 dB, bitrate=1.2 × 10-2 bpp |
Comparison original vs. compressed light fields
TotoroWaterfall
Left: the original light field. Right: the compressed light field with k = 5 and q = 2 (number of depth planes) and HEVC-QP=14. The average PSNR on all views is 35.0 dB and the average bit-rate is 0.05 bpp.
Flower
Left: the original light field. Right: the compressed light field with k = 5 and q = 2 and HEVC-QP=14. The average PSNR on all views is 37.2 dB and the average bit-rate is 0.03 bpp.
Buddha
Left: the original light field. Middle: the compressed light field with k = 15, q = 2 and HEVC-QP=2. The average PSNR on all views is 43.3 dB and the average bit-rate is 0.14 bpp. Right: the compressed light field with k = 15, q = 4 and HEVC-QP=2. The average PSNR on all views is 44.1 dB and the average bit-rate is 0.13 bpp.
Scalable light field coding
 |