A Lightweight Neural Network for Monocular View Generation with Occlusion Handling
|
S. Evain, C. Guillemot
"A Lightweight Neural Network for Monocular View Generation with Occlusion Handling", arXiv, Mars 2019. (pdf) |
Abstract
In this article, we present a very lightweight neural network architecture, trained on stereo data pairs, which performs view synthesis from one single image. With the growing success of multi-view formats, this problem is indeed increasingly relevant. The network returns a prediction built from disparity estimation, which fills in wrongly predicted regions using a occlusion handling technique. To do so, during training, the network learns to estimate the left-right consistency structural constraint on the pair of stereo input images, to be able to replicate it at test time from one single image. The method is built upon the idea of blending two predictions: a prediction based on disparity estimation, and a prediction based on direct minimization in occluded regions. The network is also able to identify these occluded areas at training and at test time by checking the pixelwise left-right consistency of the produced disparity maps. At test time, the approach can thus generate a left-side and a right-side view from one input image, as well as a depth map and a pixelwise confidence measure in the prediction. The work outperforms visually and metric-wise state-of-the-art approaches on the challenging KITTI dataset, all while reducing by a very significant order of magnitude (5 or 10 times) the required number of parameter (6.5M).
Algorithm overview
Please refer to our paper for more details.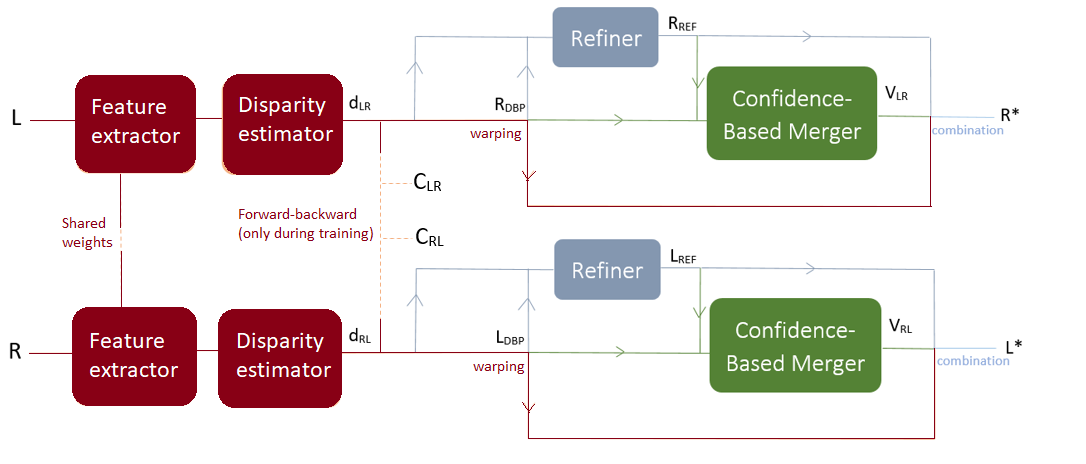
The method takes as input an image, and is able to generate left-side and right-side views from it. A first module (called Disparity-Based Predictor) estimates the disparity map and predicts an image from it by the means of warping. A second module (called REFiner) processes the result though direct minimization, which leads to a blurrier prediction, but with fewer artifacts. Finally, a third module (called Confidence-Based Merger) combines the two outputs (through a confidence map built on forward-backward consistency in the disparity maps) into one final optimized prediction.
Test datasets
KITTI Test set [1]
| Input image |  |
 |
 |
| Target image |  |
 |
 |
| Network prediction |  |
 |
 |
| Estimated disparity map |  |
 |
 |
| Confidence map |  |
 |
 |
Other urban scenes datasets
| Input image |  |
 |
 |
| Network prediction |  |
 |
 |
| Estimated disparity map |  |
 |
 |
| Confidence map |  |
 |
 |
Driving [3] | Cityscapes [2] | Rennes |
Supplementary material
Exact architecture of the various components
| Architecture of the feature extractor | 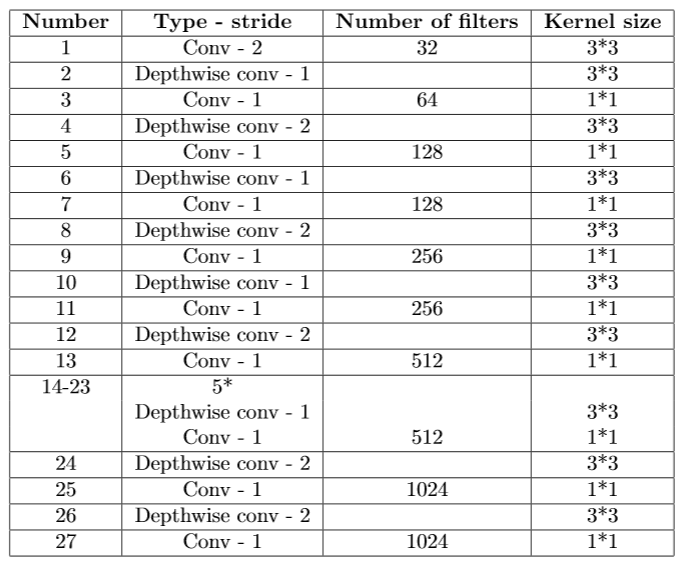 |
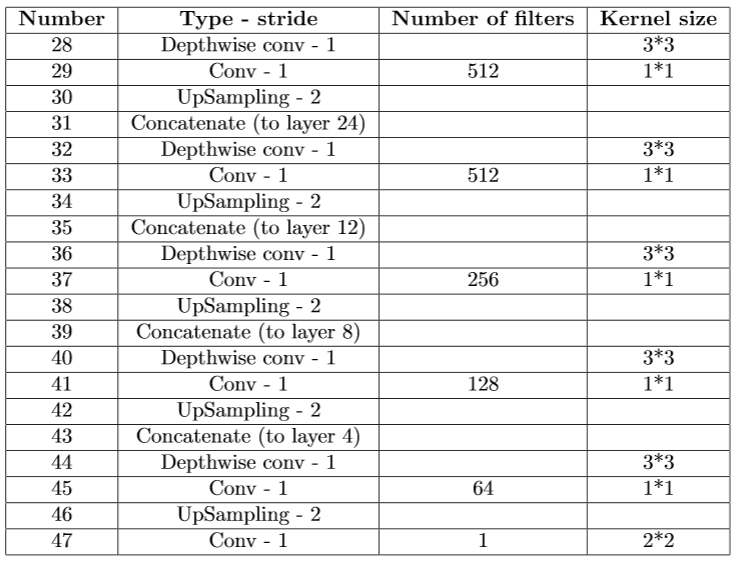 |
Architecture of the disparity estimator | Architecture of the refiner | 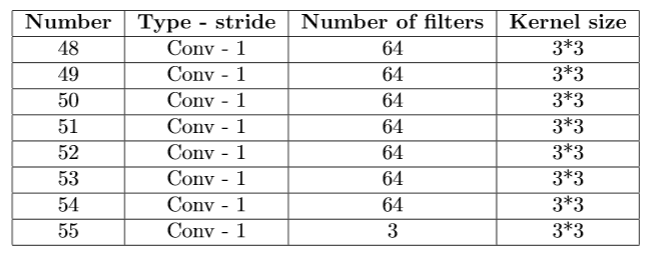 |
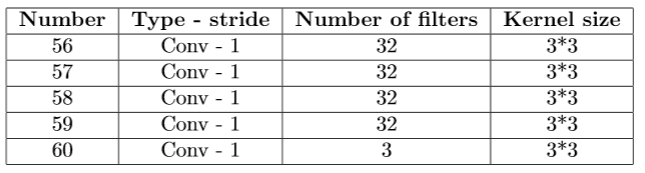 |
Architecture of the confidence map predictor |
Video of results
References
[1] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, "Vision meets robotics: The kitti dataset", International Journal of Robotics Research, 2013.[2] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban scene understanding", CVPR, 2016.
[3] N. Mayer, E. Ilg, P. Häusser, and P. Fischer, "A large dataset to train convolutional neural networks for disparity, optical flow and scene flow estimation", CVPR, 2016.