A learning based depth estimation framework for 4D densely and sparsely sampled light fields
|
Xiaoran Jiang, Jinglei Shi, Christine Guillemot,
"A learning based depth estimation framework for 4D densely and sparsely sampled light fields", ICASSP 2019.(pdf) |
Abstract
This paper proposes a learning based solution to disparity (depth) estimation for either densely or sparsely sampled light fields. Disparity between stereo pairs among a sparse subset of anchor views is first estimated by a fine-tuned FlowNet 2.0 network adapted to disparity prediction task. These coarse estimates are fused by exploiting the photo-consistency warping error, and refined by a Multi-view Stereo Refinement Network (MSRNet). The propagation of disparity from anchor viewpoints towards other viewpoints is performed by an occlusion-aware soft 3D reconstruction method. The experiments show that, both for dense and sparse light fields, our algorithm outperforms significantly the state-of-the-art algorithms, especially for subpixel accuracy.
Algorithm overview
We focus on how to handle either a dense or a sparse light field for disparity/depth estimation. Similar to [11], our algorithm only exploits a sparse subset of anchor views (four corner views), and generates one disparity map for every viewpoint of the light field. Multi-view stereo (MVS) is implemented in a deep learning based cascaded framework. A pre-trained FlowNet 2.0 is fine-tuned by pairs of stereo images, and the obtained model is used to estimate disparity between pairs of anchor views, arranged horizontally or vertically. These coarse estimates are then fused at each anchor viewpoint by exploiting the warping error from other anchor viewpoints, and then refined by a second convolutional neural network (CNN), which we call Multi-view Stereo Refinement Network (MSRNet). For better subpixel accuracy of the disparity values, views are upsampled before being fed to CNNs. Correspondingly, the output disparity maps are rescaled. The propagation of disparity from anchor viewpoints towards other viewpoints is performed by an occlusion-aware soft 3D reconstruction method.Please refer to our paper for more details.
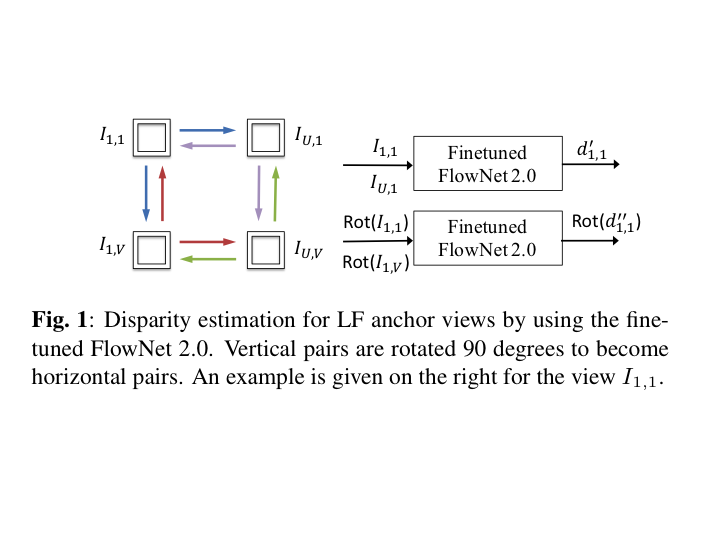 |
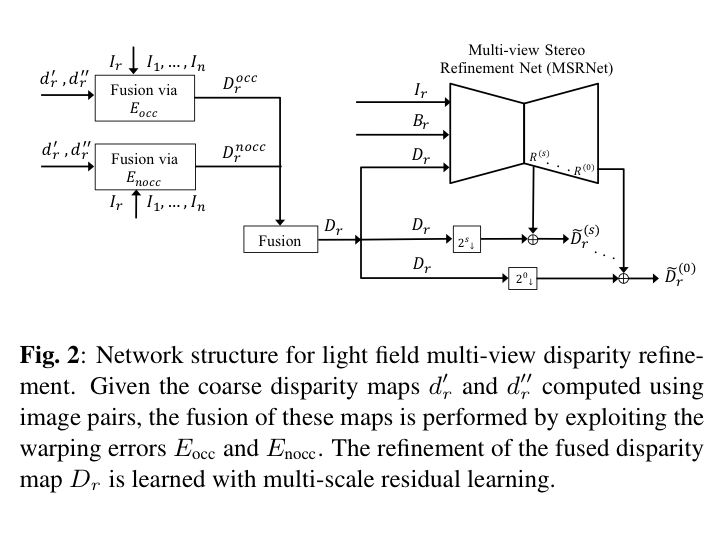 |
Test datasets
Both dense and sparse light fields are considered. The center 7 × 7 sub-aperture views are considered for dense light fields, and 3 × 3 sub-aperture views are considered for sparse light fields.
Butterfly
Still-life
MonasRoom
Cotton
Boxes
Sideboard
Dino
Stilllife
Dino
Zhang et al.[5]: Shuo Zhang, Hao Sheng, Chao Li, Jun Zhang, and Zhang Xiong, "Robust depth estimation for light field via spinning parallelogram operator," Journal Computer Vision and Image Understanding, 2016.
Jiang et al.[11]: Xiaoran Jiang, Mikael Le Pendu, and Christine Guillemot, "Depth estimation with occlusion handling from a sparse set of light field views," in IEEE International Conference on Image Processing (ICIP), 2018.
Huang et al.[10]: Chao-Tsung Huang, "Empirical bayesian light-field stereo matching by robust pseudo random field modeling," IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018.
Dense light fields
 |
 |
 |
 |
 |
 |
 |
 |
| Buddha [-1.5, 0.9] | Butterfly [-0.9, 1.2] | Stilllife [-2.6, 2.8] | MonasRoom [-0.8, 0.8] | Cotton [-1.4, 1.5] | Sideboard [-1.4, 1.9] | Boxes [-1.3, 2.0] | Dino [-1.7, 1.8] |
Sparse light fields
 |
 |
 |
 |
| Furniture [-13.6, 12.7] | Lion [-3.2, 14.4] | Toy_bricks [-0.4, 11.0] | Electro_devices [-4.9, 8.3] |
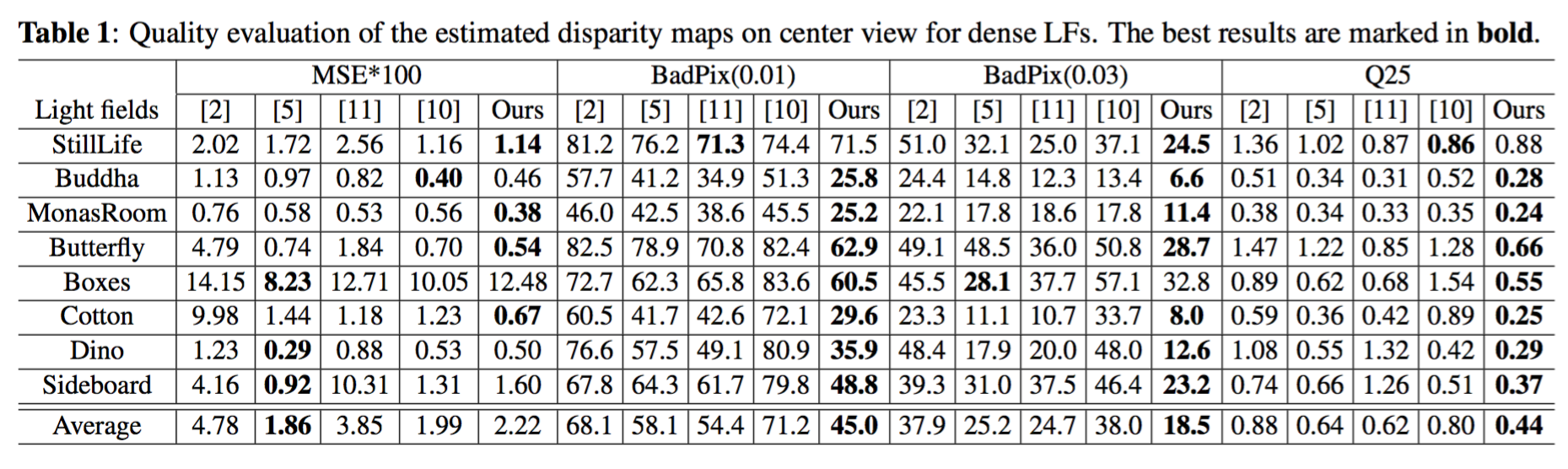
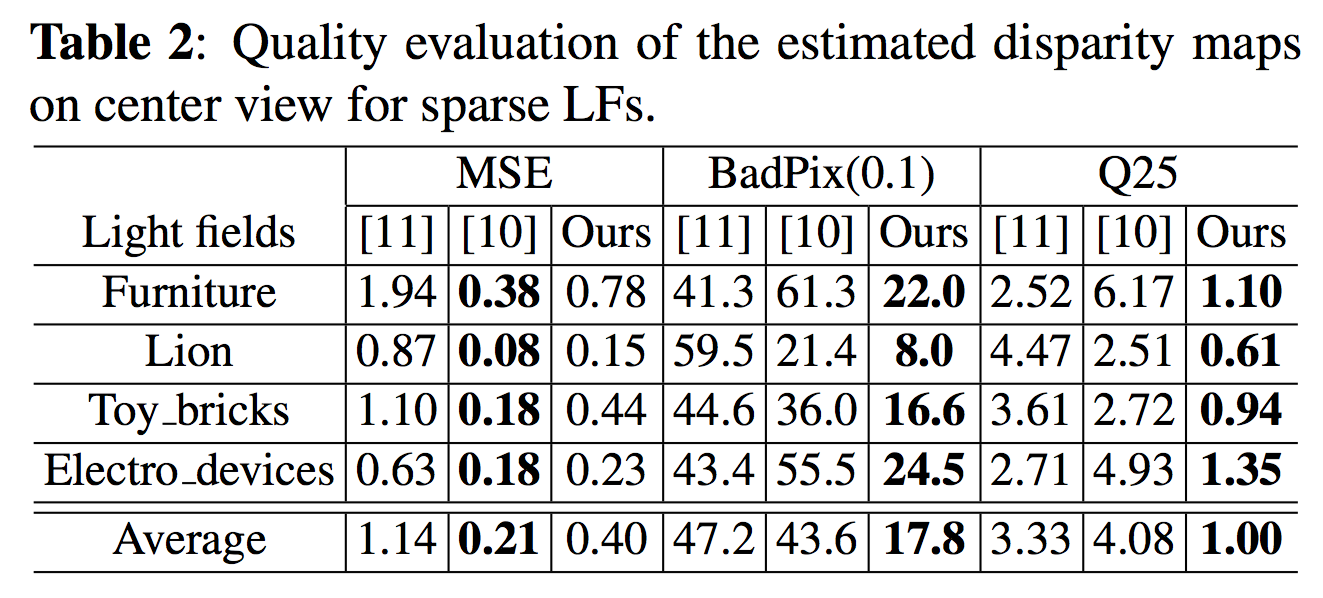
Quantitative assessment (center view)
Visual comparison (center view)
Buddha| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Butterfly
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Still-life
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
MonasRoom
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
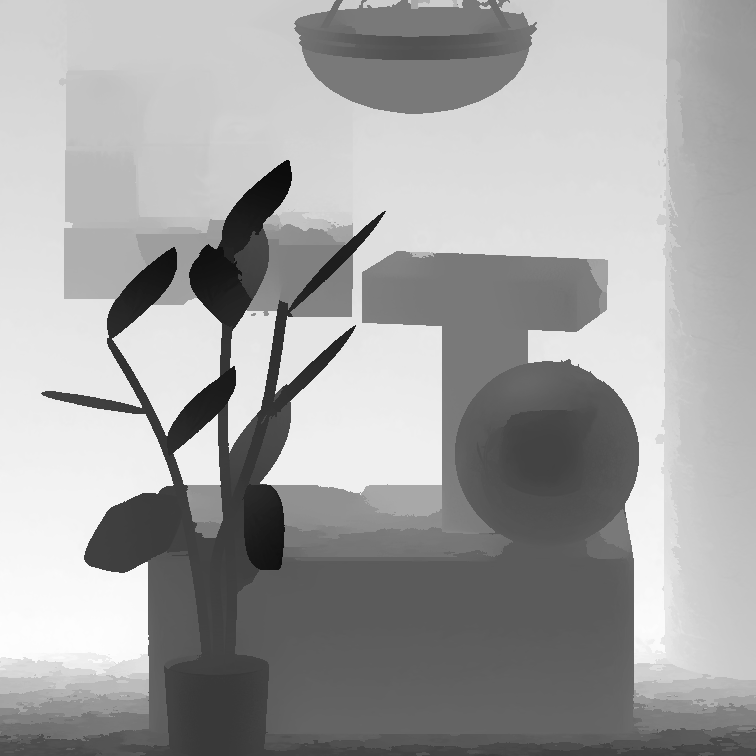 |
 |
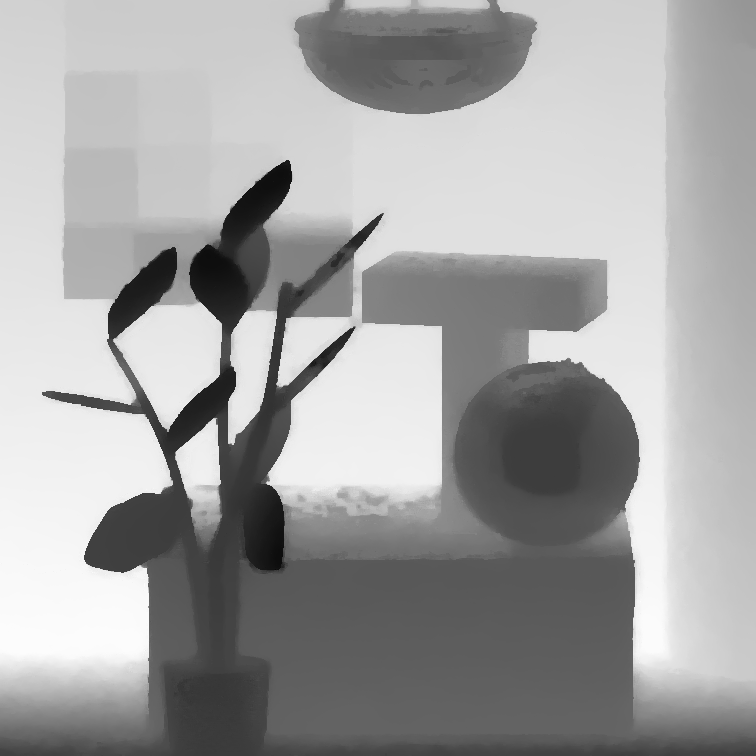 |
 |
 |
 |
Cotton
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Boxes
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Sideboard
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Dino
| Jeon et al. [2] | Zhang et al. [5] | Jiang et al. [11] | Huang et al. [10] | Ours | GT |
 |
 |
 |
 |
 |
 |
Estimated disparity maps for all the views
MonasRoomStilllife
Dino
References
Jeon et al.[2]: Hae-Gon Jeon, Jaesik Park, Gyeongmin Choe, Jinsun Park, Yunsu Bok, Yu-Wing Tai, and In So Kweon, "Accurate depth map estimation from a lenslet light field camera," in International Conference on Computer Vision and Pattern Recognition (CVPR), 2015.Zhang et al.[5]: Shuo Zhang, Hao Sheng, Chao Li, Jun Zhang, and Zhang Xiong, "Robust depth estimation for light field via spinning parallelogram operator," Journal Computer Vision and Image Understanding, 2016.
Jiang et al.[11]: Xiaoran Jiang, Mikael Le Pendu, and Christine Guillemot, "Depth estimation with occlusion handling from a sparse set of light field views," in IEEE International Conference on Image Processing (ICIP), 2018.
Huang et al.[10]: Chao-Tsung Huang, "Empirical bayesian light-field stereo matching by robust pseudo random field modeling," IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018.