A Framework for Learning Based Depth from a Flexible Subset of Dense and Sparse Light Field Views
|
Jinglei Shi, Xiaoran Jiang, Christine Guillemot,
"A Framework for Learning Based Depth from a Flexible Subset of Dense and Sparse Light Field Views", TIP, July, 2019.(pdf) |
Abstract
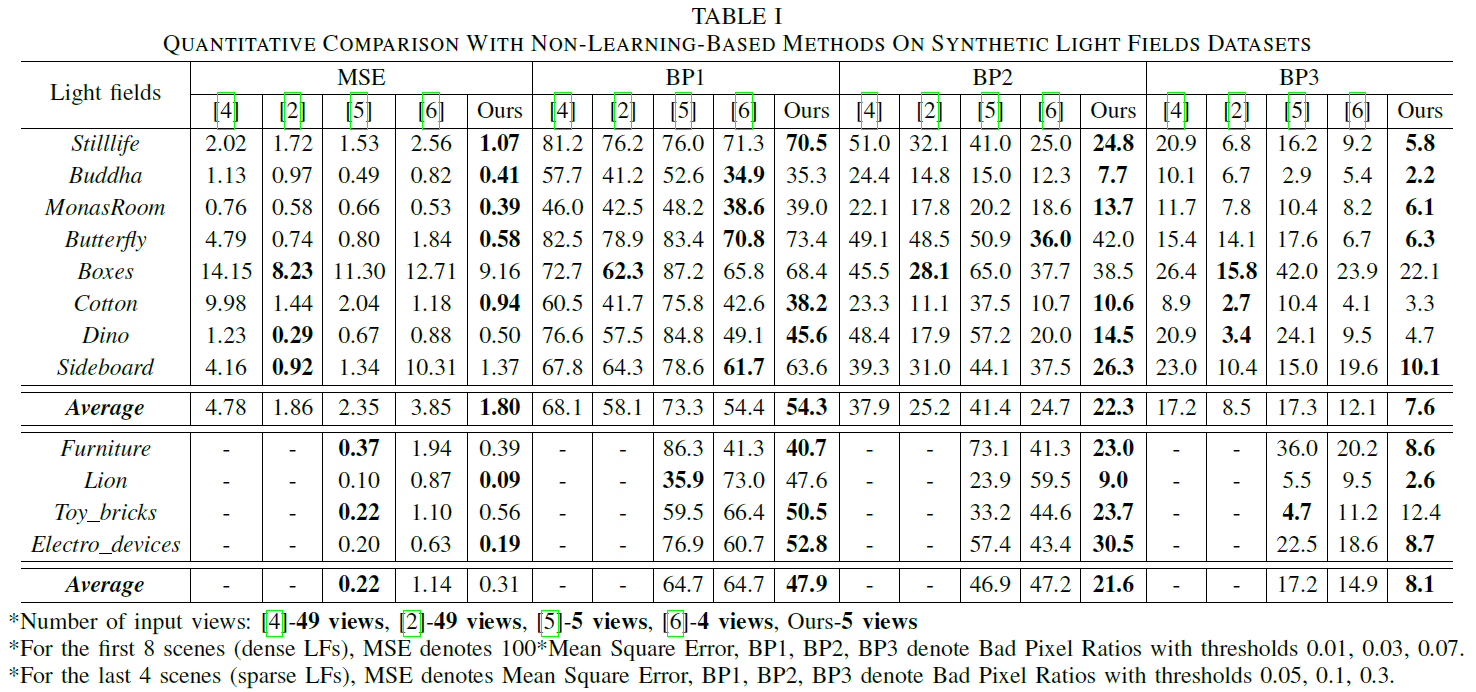
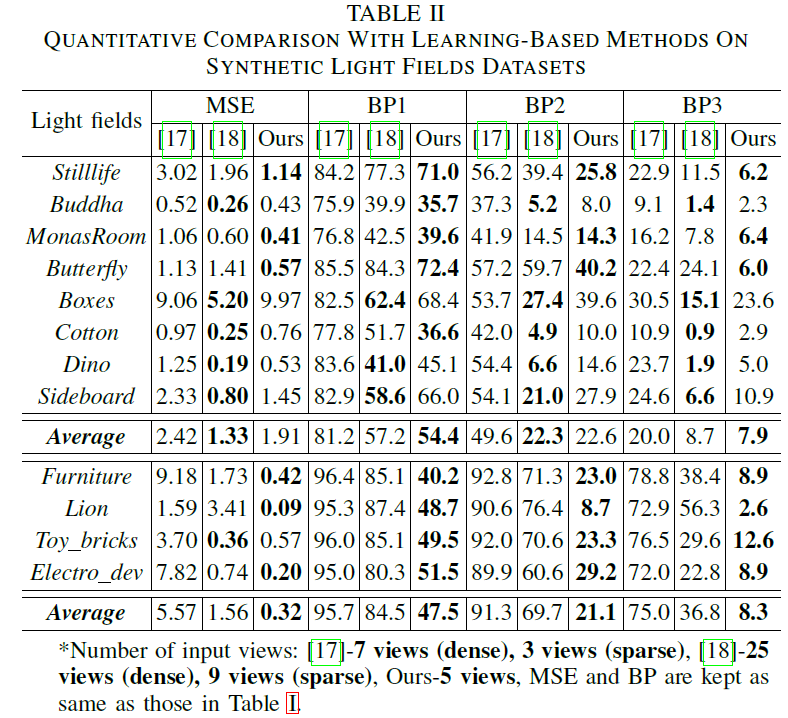
In this paper, we propose a learning based depth estimation framework suitable for both densely and sparsely sampled light fields. The proposed framework consists of three processing steps: initial depth estimation, fusion with occlusion handling, and refinement. The estimation can be performed from a flexible subset of input views. The fusion of initial disparity estimates, relying on two warping error measures, allows us to have an accurate estimation in occluded regions and along the contours. In contrast with methods relying on the computation of cost volumes, the proposed approach does not need any prior information on the disparity range. Experimental results show that the proposed method outperforms state-of-the-art light fields depth estimation methods, including prior methods based on deep neural architectures.
Algorithm overview
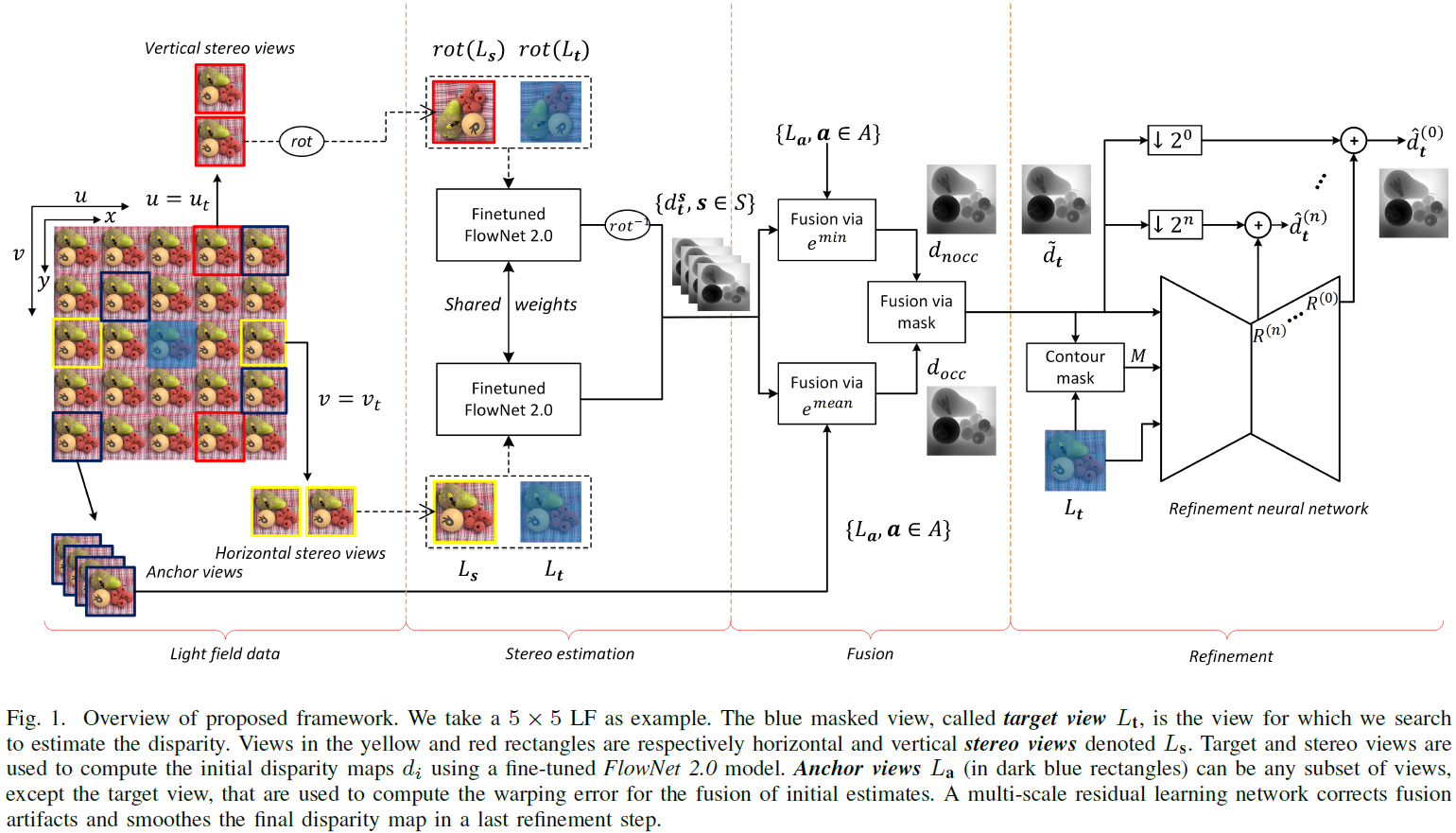
We propose a supervised deep learning framework for estimating scene depth, taking at the input a flexible subset of light field views. In order to compute scene depth, the proposed approach estimates disparity maps for every viewpoint of the light field. Hence, in the rest of the paper, we will refer to disparity estimation only. The use of subsets of input views allows us, compared to stereo estimation methods, to increase the estimation accuracy, while limiting computational complexity. Initial disparity estimates are computed between aligned stereo pairs using the FlowNet 2.0 optical flow estimation architecture that we fine-tuned to be suitable for disparity estimation in dense and sparse light fields. These initial estimates are used to warp a flexible set of anchor views onto a target viewpoint. The fusion of these initial estimates relying on a winner-takes-all (WTA) strategy with two measures of warping errors reflecting disparity inaccuracy in occlusion-free and occlusions respectively, allows us to have an accurate disparity estimation in occluded regions and along the contours. A refinement network is then proposed to learn the disparity maps residuals at different scales.
Please refer to our paper for more details.
Two synthetic light field datasets
In this paper, we have released two synthetic light field datasets, including all sub-aperture views and corresponding depth maps. The released datasets contain a densely sampled dataset (DLFD) and a sparsely sampled one (SLFD). Please refer to Inria synthetic light field datasets for more details.
Test datasets
The algorithm is tested on densely/sparsely sampled synthetic/genuine light field data. The center 7 × 7 sub-aperture views are considered for densely sampled light fields, and 3 × 3 sub-aperture views are considered for sparsely sampled light fields.
Buddha
Butterfly
MonasRoom
Boxes
Cotton
Dino
Sideboard
Duck
Fruits
Rose
Bikes
Stone_pillars_inside
Lion
Path
Titus
Zhang et al.[2]: Shuo Zhang, Hao Sheng, Chao Li, Jun Zhang, and Zhang Xiong, "Robust depth estimation for light field via spinning parallelogram operator," Journal Computer Vision and Image Understanding, 2016.
Jiang et al.[5]: Xiaoran Jiang, Mikael Le Pendu, and Christine Guillemot, "Depth estimation with occlusion handling from a sparse set of light field views," in IEEE International Conference on Image Processing (ICIP), 2018.
Huang et al.[6]: Chao-Tsung Huang, "Empirical bayesian light-field stereo matching by robust pseudo random field modeling," IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018.
Heber et al.[17]: Stefan Heber, Wei Yu, Thomas Pock, "Neural EPI-Volume network for shape from light field," in International Conference on Computer Vision (ICCV), 2017.
Shin et al.[18]: Changha Shin, Hae-Gon Jeon, Youngjin Yoon, In So Kweon, Seon Joo Kim, "EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth From Light Field Images," in International Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
Densely sampled synthetic light fields
 |
 |
 |
 |
 |
 |
 |
 |
| Stilllife [-2.6, 2.8] | Buddha [-1.5, 0.9] | Butterfly [-0.9, 1.2] | MonasRoom [-0.8, 0.8] | Boxes [-1.3, 2.0] | Cotton [-1.4, 1.5] | Sideboard [-1.4, 1.9] | Dino [-1.7, 1.8] |
Sparsely sampled synthetic light fields
 |
 |
 |
 |
| Furniture [-13.6, 12.7] | Lion [-3.2, 14.4] | Toys_bricks [-0.4, 11.0] | Electro_devices [-4.9, 8.3] |
Densely sampled real-world light fields
 |
 |
 |
 |
 |
| Duck [-0.6, 3.4] | Fruits [-1.1, -0.1] | Rose [-1.1, -0.2] | Bikes [-1.1, 1.2] | Stone_pillars_inside [-0.9, 0.8] |
Sparsely sampled real-world light fields
 |
 |
| Path [-1.0, -44.6] | Titus [-3.5, -60.3] |
Quantitative assessment (center view)
Visual comparison (center view)
Densely sampled light fields
Stilllife |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Buddha
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Butterfly
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
MonasRoom
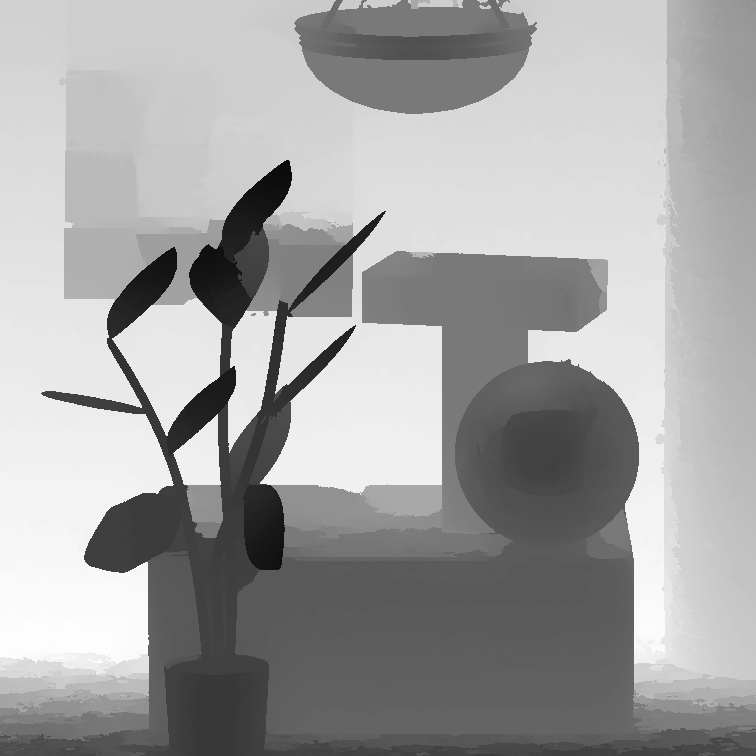 |
 |
 |
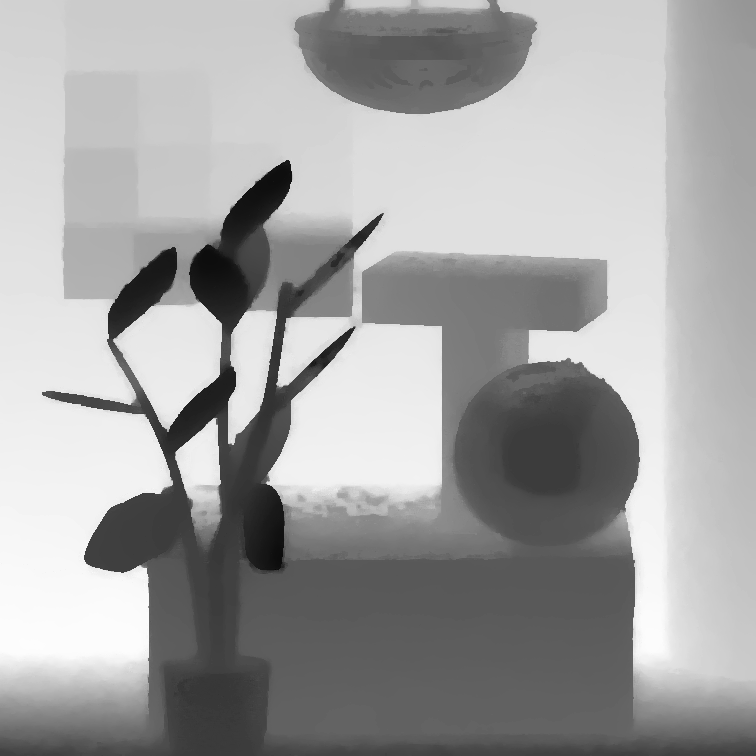 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Boxes
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Cotton
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Dino
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Sideboard
 |
 |
 |
 |
 |
 |
 |
 |
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Duck
 |
 |
 |
 |
 |
 |
 |
|
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Fruits
 |
 |
 |
 |
 |
 |
 |
|
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Rose
 |
 |
 |
 |
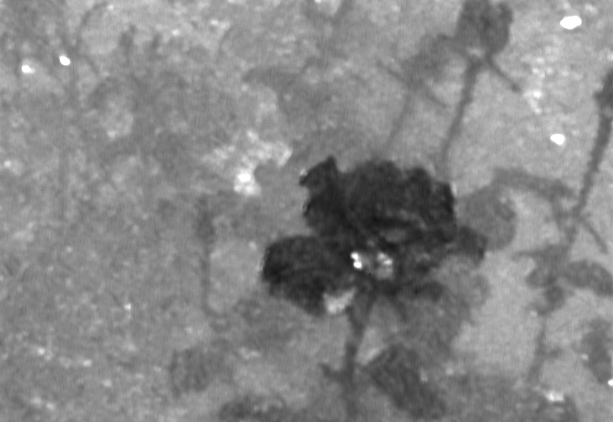 |
 |
 |
|
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Bikes
 |
 |
 |
 |
 |
 |
 |
|
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Stone_pillars_inside
 |
 |
 |
 |
 |
 |
 |
|
| Jeon et al. [4] | Zhang et al. [2] | Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Sparsely sampled light fields
Furniture |
 |
 |
 |
 |
 |
| Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Lion
 |
 |
 |
 |
 |
 |
| Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | GT |
Path
 |
 |
 |
 |
 |
|
| Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
Titus
 |
 |
 |
 |
 |
|
| Huang [5] | Jiang et al. [6] | Heber et al. [17] | Shin et al. [18] | Ours | Image |
References
Jeon et al.[4]: Hae-Gon Jeon, Jaesik Park, Gyeongmin Choe, Jinsun Park, Yunsu Bok, Yu-Wing Tai, and In So Kweon, "Accurate depth map estimation from a lenslet light field camera," in International Conference on Computer Vision and Pattern Recognition (CVPR), 2015.Zhang et al.[2]: Shuo Zhang, Hao Sheng, Chao Li, Jun Zhang, and Zhang Xiong, "Robust depth estimation for light field via spinning parallelogram operator," Journal Computer Vision and Image Understanding, 2016.
Jiang et al.[5]: Xiaoran Jiang, Mikael Le Pendu, and Christine Guillemot, "Depth estimation with occlusion handling from a sparse set of light field views," in IEEE International Conference on Image Processing (ICIP), 2018.
Huang et al.[6]: Chao-Tsung Huang, "Empirical bayesian light-field stereo matching by robust pseudo random field modeling," IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018.
Heber et al.[17]: Stefan Heber, Wei Yu, Thomas Pock, "Neural EPI-Volume network for shape from light field," in International Conference on Computer Vision (ICCV), 2017.
Shin et al.[18]: Changha Shin, Hae-Gon Jeon, Youngjin Yoon, In So Kweon, Seon Joo Kim, "EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth From Light Field Images," in International Conference on Computer Vision and Pattern Recognition (CVPR), 2018.