Graph-based light fields representation and coding using geometry information
|
|
X. Su, M. Rizkallah, T. Maugey, C. Guillemot,
"Graph-based light fields representation and coding using geometry information", IEEE International Conference on Image Processing (ICIP), Beijing, 17-20 Sept. 2017.(pdf) |

Abstract
Data sets
|
|
|
|
|
|
|
|




Graph-based representation
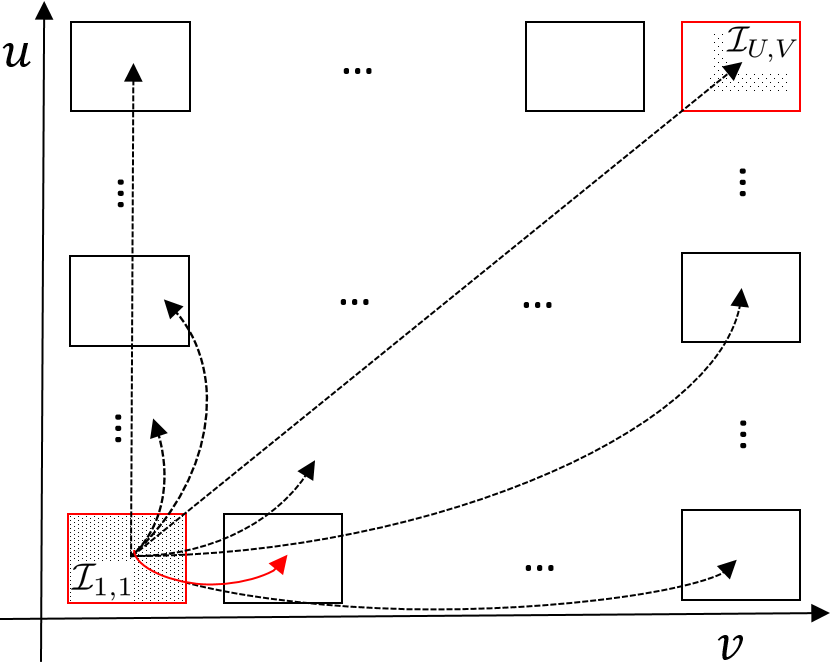
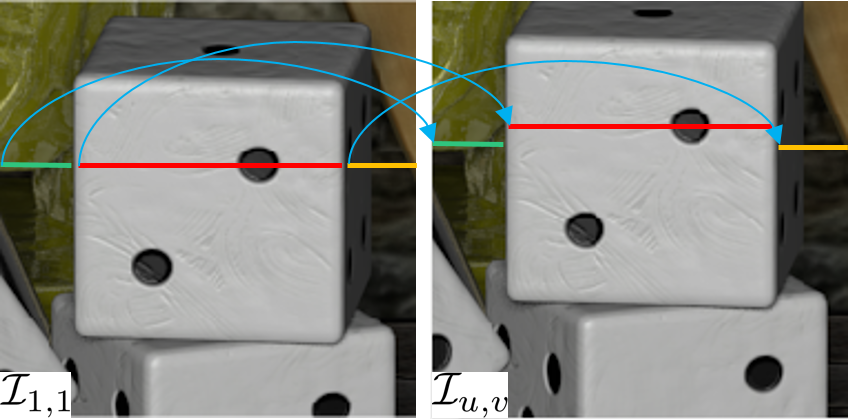
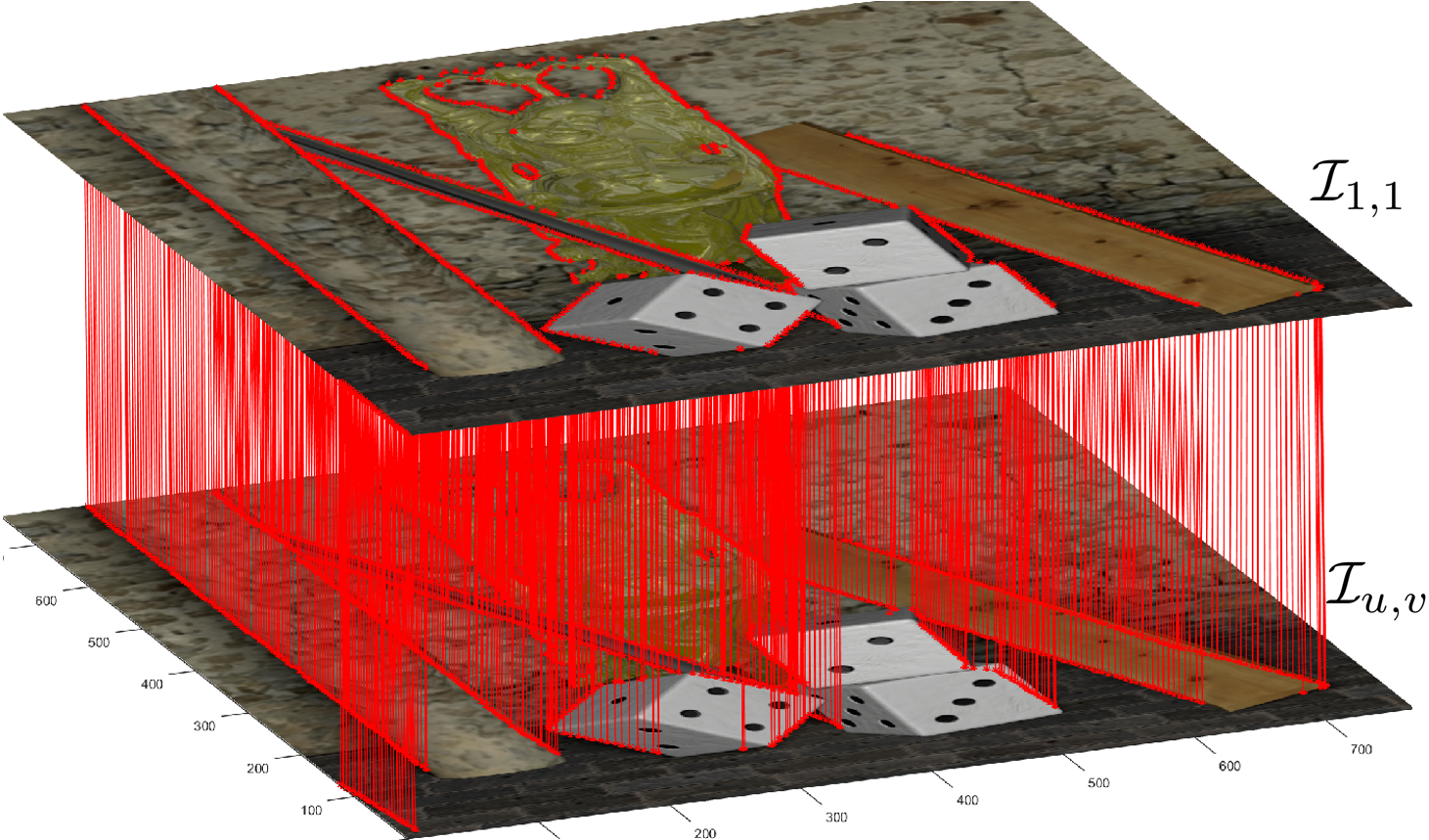
The graph connections are derived from the disparity and hold just enough information to synthesize other sub-aperture images from one reference image of the LF. Based on the concept of epipolar segment, the graph connections are sparsified (less important segments are removed) by a rate-distortion optimization. Fig. 1.(c) gives an illustration of the kept graph connections between I1,1 and Iu,v.
|
|
|
|
|
(a) GBR for light field |
(b) Example of graph connections between two views. |
(c) Graph connections between two views. |
|
Fig.1. Graph based representation (GBR) adapted to light fields |
||
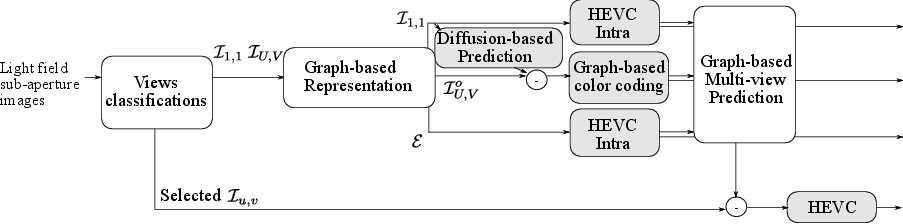
Coding Scheme
|
|
|
Fig.2. Proposed encoder |
-
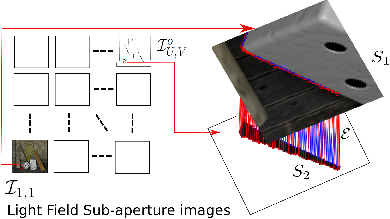
Fig.3. Connections of the disoccluded pixels.
Results
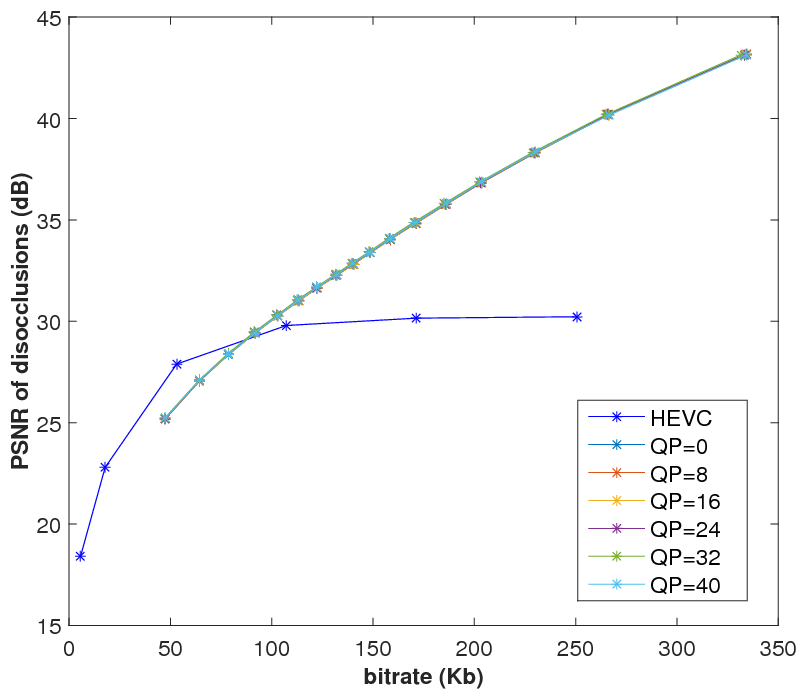
Evaluation of GFT
|
|
|
|
|
|
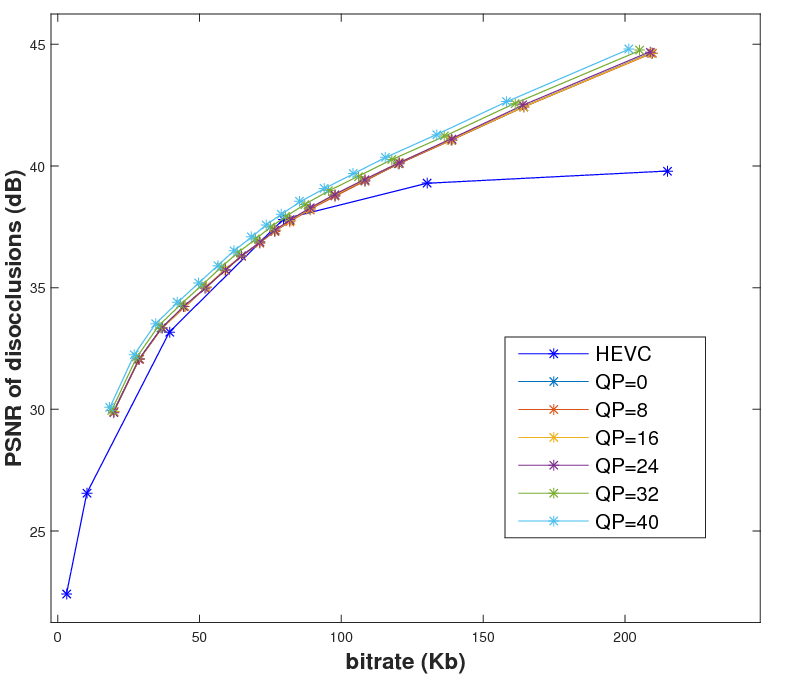
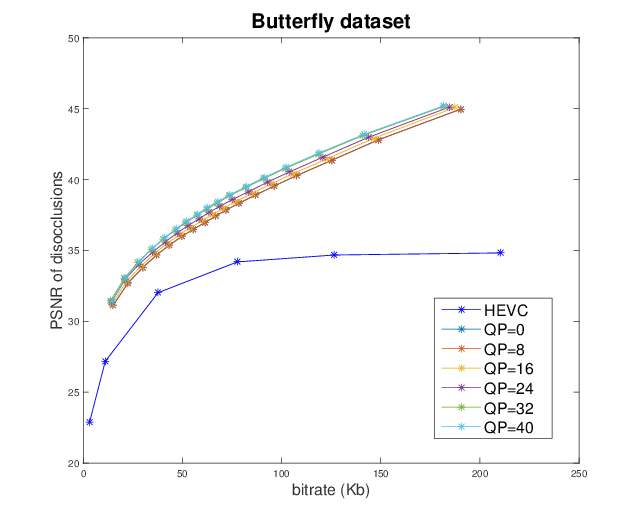
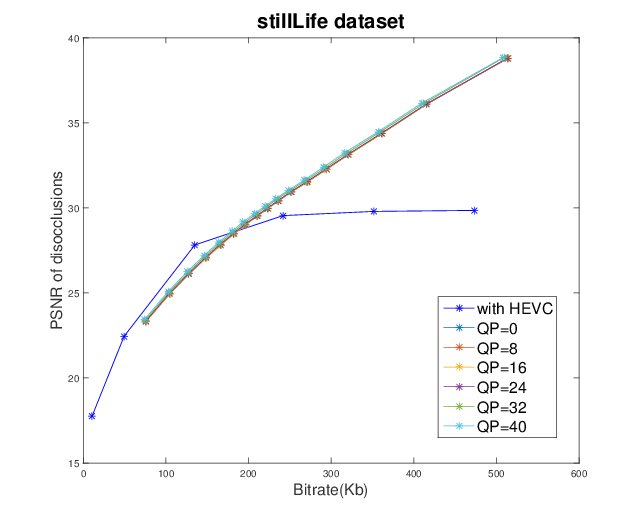
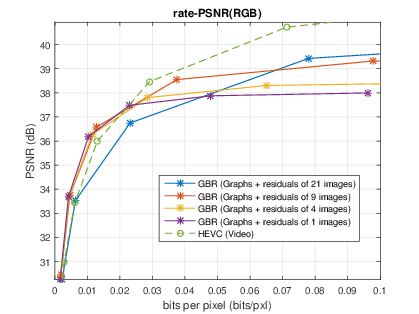
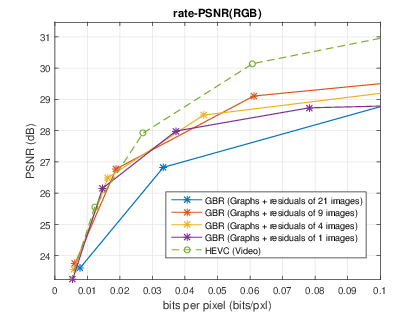
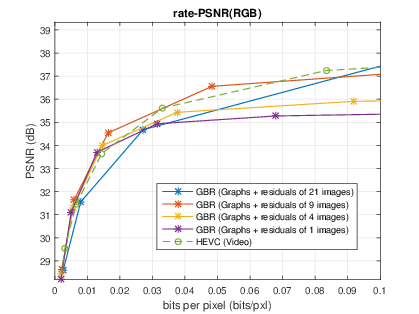
Light field representation and compression
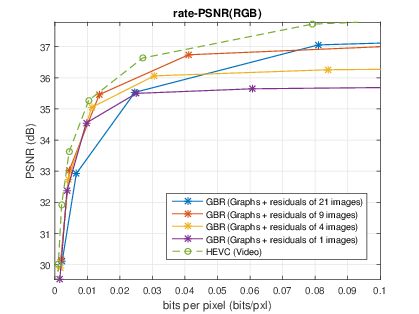
The number of sub-aperture images selected to add residuals is chosen as {1,4,9,21} with a regular sub-sampling pattern. The baseline method is the scheme which directly compresses the whole LF dataset as a video sequence with HEVC. At low bitrate, the proposed GBR can yield PSNR-rate gain. However, at high bitrate, the GBR scheme is outperformed by HEVC, due to the limited number of selected sub-aperture images.|
|
|
|
|
|
|
GBR |
Original |
HEVC |
|
|
||
|
|
||
|
|
||
|
|
||


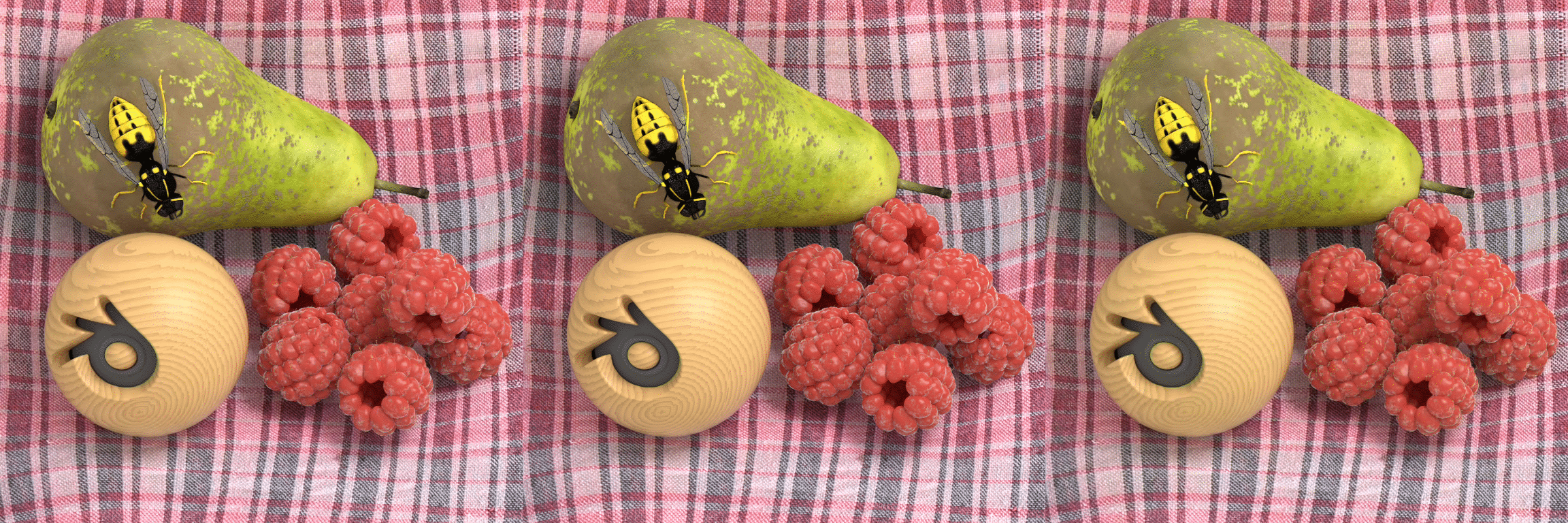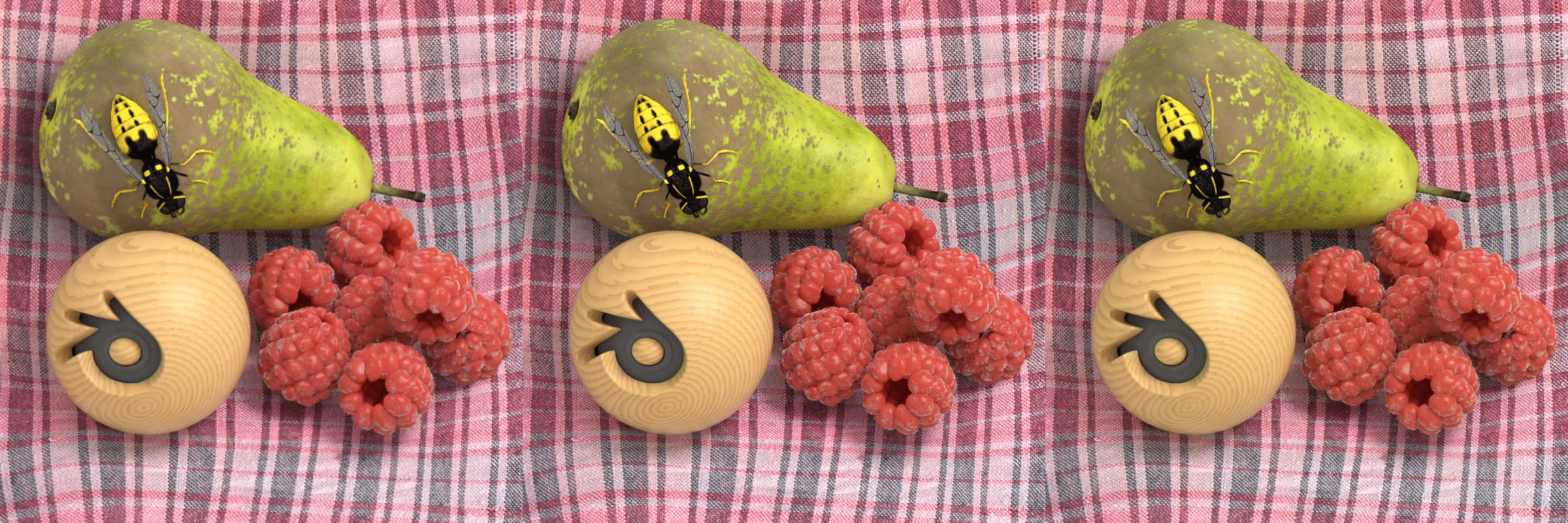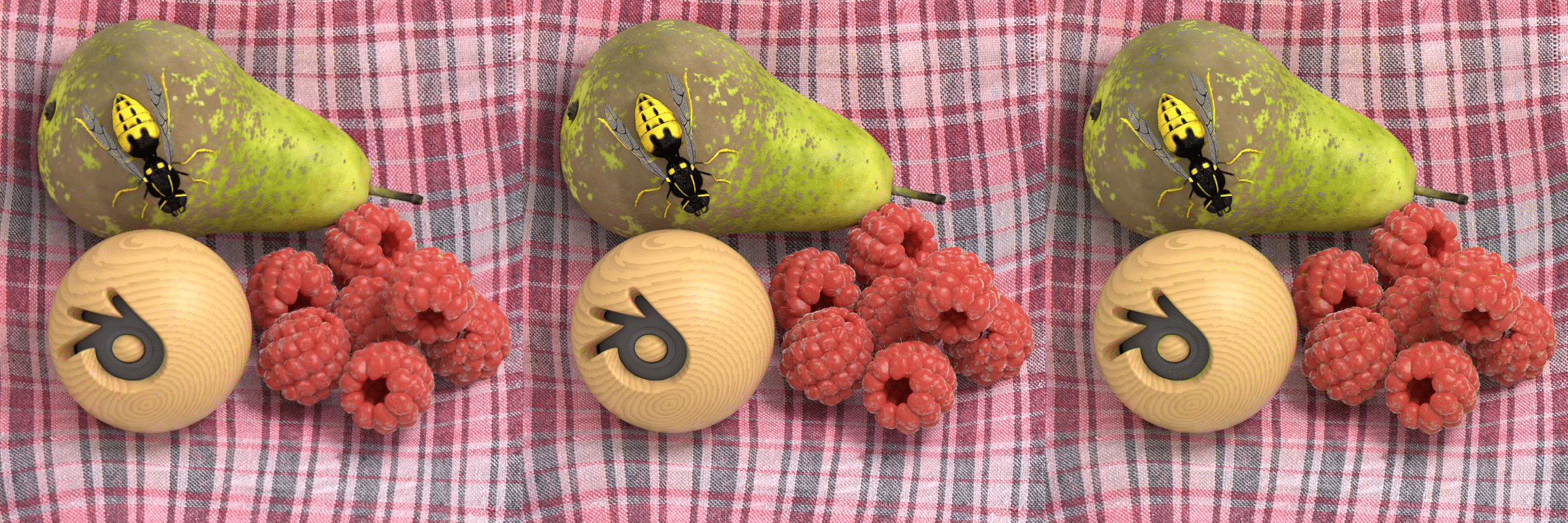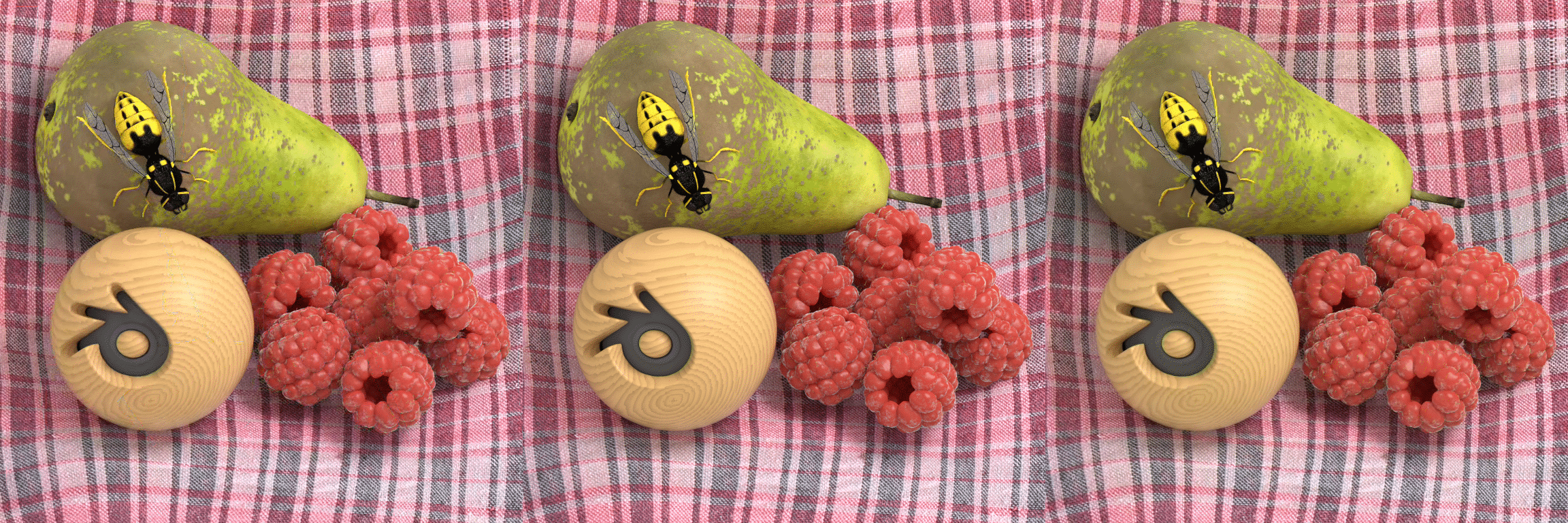

References
[1] Sven Wanner, Stephan Meister, and Bastian Goldluecke, “Datasets and Benchmarks for Densely Sampled 4D Light Fields,” in VMV. Citeseer, 2013, pp. 225–226.
[2] Blender, “Blender,” https://www.blender.org/, [Online].
[3] Thomas Maugey, Antonio Ortega, and Pascal Frossard, “Graph-based representation for multiview image geometry,” IEEE Transactions on Image Processing, vol. 24, no. 5, pp. 1573–1586, 2015.
[4] Xin Su, Thomas Maugey, and Christine Guillemot, “Rate-Distortion Optimized Graph-Based Representation for Multiview with Complex Camera Configurations,” IEEE Trans. on Image Processing, submitted, 2017.
[5] Xin Su, Thomas Maugey, and Christine Guillemot, “Graph-based representation for multiview images with complex camera configurations,” in Image Processing (ICIP), 2016 IEEE International Conference on. IEEE, 2016, pp. 1554–1558.
[6] David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst, “The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains,” IEEE Signal Processing Magazine, vol. 30, no. 3, pp. 83–98, 2013.