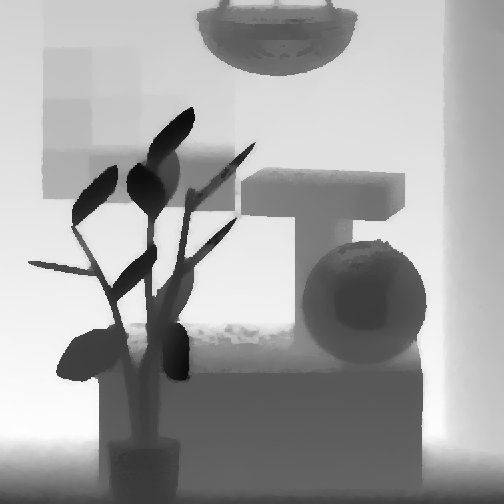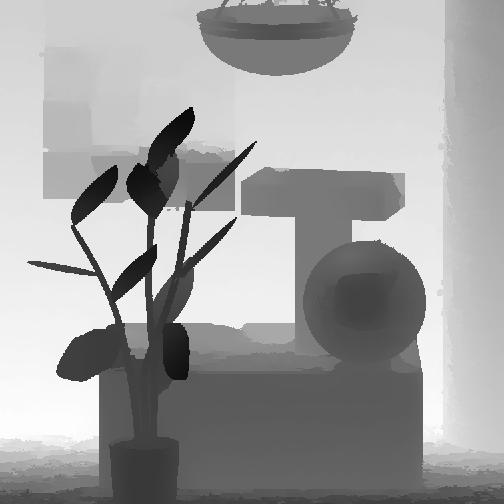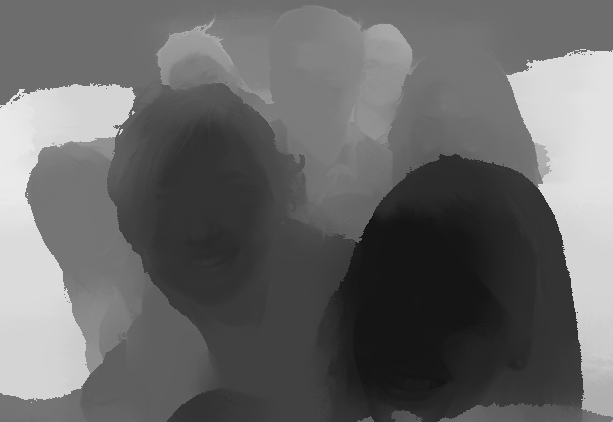This paper addresses the problem of depth estimation for every viewpoint of a dense light field, exploiting information from only a sparse set of views. This problem is particularly relevant for applications such as light field reconstruction from a subset of views, for view synthesis and for compression. Unlike most existing methods for scene depth estimation from light fields, the proposed algorithm computes disparity (or equivalently depth) for every viewpoint taking into account occlusions. In addition, it preserves the continuity of the depth space and does not require prior knowledge on the depth range. The experiments show that, both for synthetic and real light fields, our algorithm achieves competitive performance to state-of-the-art algorithms which exploit the entire light field and usually yield to the depth map for the center viewpoint only.
Algorithm overview
Please refer to our paper for more details.
The algorithm proceeds as follows. The four corner views are taken as input, since these views contain the geometry of the whole scene, accounting for disocclusions. Multiple disparity candidates for these input views are first computed using an optical flow estimator. These candidates are then aggregated by using a variational energy minimization and the resulting map per input view is further enhanced by using a novel superpixel-based bilateral filtering. These refined disparity maps are warped to novel viewpoints and a global inpainting using low rank approximation is performed to fill the holes. Finally, at each novel viewpoint, warped candidates are merged with respect to their disparity uncertainty via a winner-take-all process. Please refer to the paper for more details.
Test datasets
In this work, both the synthetic light fields from HCI datasets and the real light fields captured by Lytro Illum cameras from INRIA and EPFL datasets are considered. The center 7 × 7 sub-aperture views are considered for all test light fields. The Illum light fields are decoded and extracted by Dansereau's Matlab Light Field Toolbox.
HCI synthetic light fields
Buddha
Butterfly
Stilllife
MonasRoom
Cotton
Sideboard
Boxes
Dino
INRIA light fields
Fruits
Rose
Duck
Bench
EPFL light fields
Friends
FontainVincent
StonePillarsOutside
Bikes
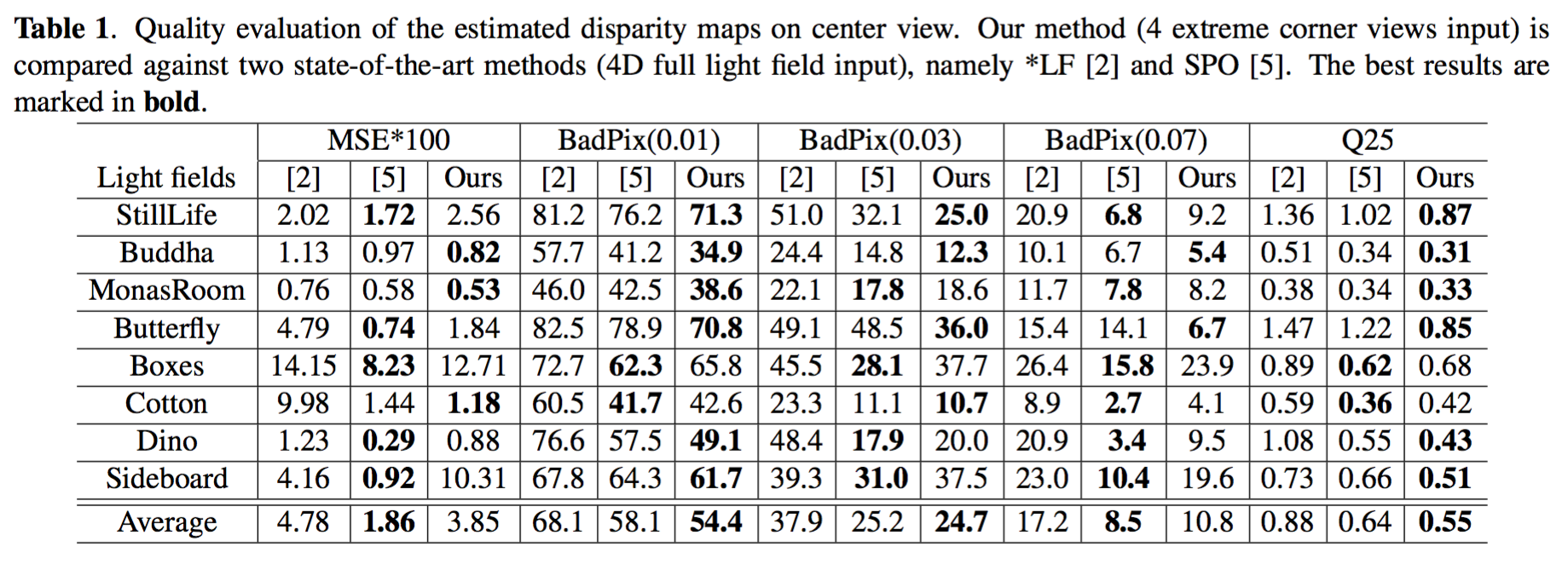
Quantitative assessment (center view)
Visual comparison (center view)
Our method (with 4 corner views input) is compared against two state-of-the-art methods, *LF and SPO (4D light field input). Unlike the compared methods, our method does not require prior knowledge on the depth range.
HCI synthetic light fields
Buddha, [-1.5, 0.9]
Ours
*LF
SPO
GT
Butterfly, [-0.9, 1.2]
Ours
*LF
SPO
GT
Still-life, [-2.6, 2.8]
Ours
*LF
SPO
GT
MonasRoom, [-0.8, 0.8]
Ours
*LF
SPO
GT
Cotton, [-1.4, 1.5]
Ours
*LF
SPO
GT
Boxes, [-1.3, 2.0]
Ours
*LF
SPO
GT
Sideboard, [-1.4, 1.9]
Ours
*LF
SPO
GT
Dino, [-1.7, 1.8]
Ours
*LF
SPO
GT
Lytro Illum light fields
Bikes, [-1.1, 1.2]
Ours
*LF
SPO
Friends, [-0.3, 0.5]
Ours
*LF
SPO
FontainVincent, [-0.6, 0.7]
Ours
*LF
SPO
StonePillarsOutside, [-0.9, 0.8]
Ours
*LF
SPO
Fruits, [-1.1, -0.1]
Ours
*LF
SPO
Rose, [-1.1, -0.2]
Ours
*LF
SPO
Bench, [-0.8, -0.1]
Ours
*LF
SPO
Duck, [-0.6, 3.4]
Ours
*LF
SPO
Estimated disparity maps for all the views
MonasRoom
Cotton
Rose
References
*LF: Hae-Gon Jeon, Jaesik Park, Gyeongmin Choe, Jinsun Park, Yunsu Bok, Yu-Wing Tai, and In So Kweon, "Accurate depth map estimation from a lenslet light field camera," in International Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
SPO: Shuo Zhang, Hao Sheng, Chao Li, Jun Zhang, and Zhang Xiong, "Robust depth estimation for light field via spinning parallelogram operator," Journal Computer Vision and Image Understanding, vol.145, pp. 148-159, 2016.