Super Resolution of Light Field Images using Linear Subspace Projection of Patch-Volumes
 |
R. Farrugia, C. Galea, C. Guillemot,
"Super Resolution of Light Field Images using Linear Subspace Projection of Patch-Volumes", IEEE Journal on Selected Topics in Signal Processing (J-STSP), vol. 11, No. 7, pp. 1058-1071, Oct. 2017.(pdf) Collaboration with Prof. Reuben Farrugia, University of Malta. |
Abstract
This paper describes
an example-based super-resolution algorithm for light fields,
which allows the increase of the spatial resolution of the different
views in a consistent manner across all sub-aperture images of
the light field. The algorithm learns linear projections between
subspaces of reduced dimension in which reside patch-volumes
extracted from the light field. The method is extended to cope
with angular super-resolution, where 2D patches of intermediate
sub-aperture images are approximated from neighbouring subaperture
images using multivariate ridge regression. Experimental
results show significant quality improvement when compared
to state-of-the-art single-image super-resolution methods applied
on each view separately, as well as when compared to a recent
light field super-resolution technique based on deep learning.
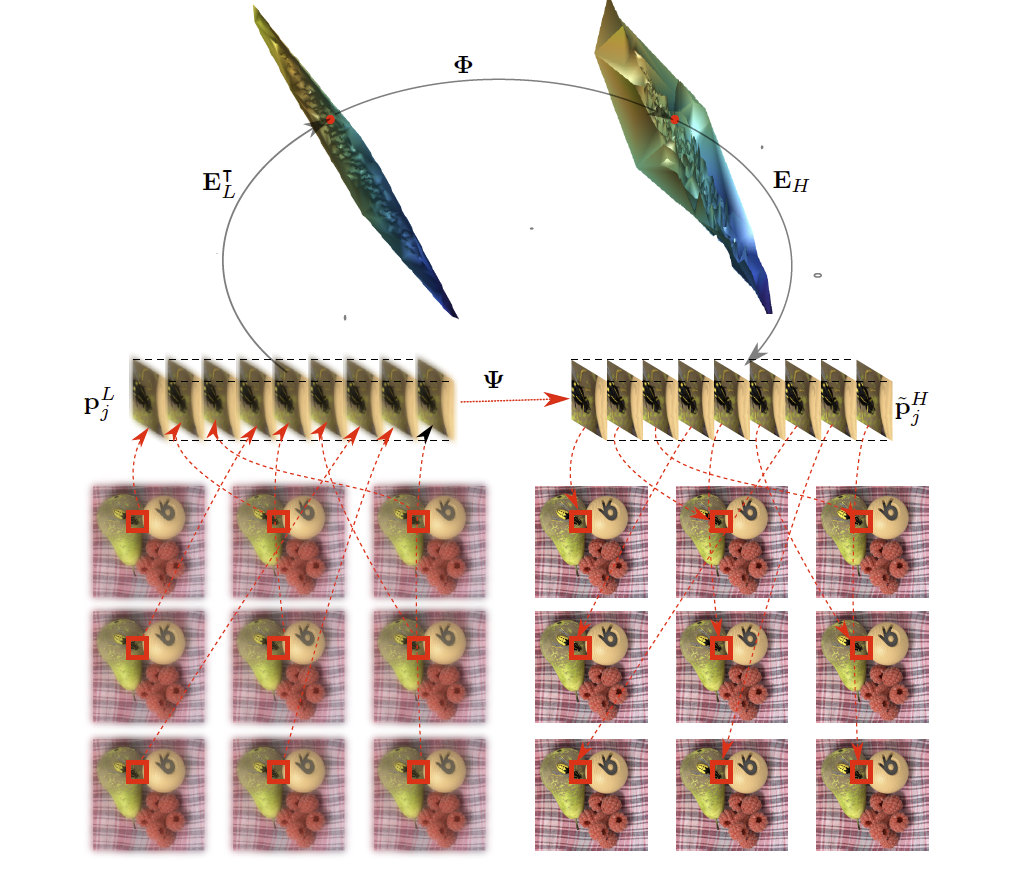
Learning linear projections between subspaces of low and high resolution patch-volumes
To maintain consistency across all sub-aperture images of the light field, the proposed method operates on 3D stacks (called patch-volumes) of 2D-patches, extracted from
the different sub-aperture images. The patches forming the 3D stack are either co-located patches or best matches across subaperture images. A dictionary of examples is first constructed by extracting, from a training set of high- and low- resolution
light fields, pairs of high- and low-resolution patch-volumes.
These patch-volumes are of very high dimension. Nevertheless, they contain a lot
of redundant information, hence actually lie on subspaces of
lower dimension. The low- and high-resolution patch-volumes
of each pair can therefore be projected on their respective lowand
high-resolution subspaces, e.g. using Principal Component Analysis (PCA).
The dictionary of pairs of projected patch-volumes (the examples) map locally the relation between the high-resolution patchvolumes and their low-resolution (LR) counterparts. A linear mapping function is then learned, using Multivariate Ridge Regression (RR), between the subspaces of the low- and highresolution patch-volumes. Each overlapping patch-volume of the low-resolution light field can then be super-resolved by a straight application of the learned mapping function.
The above method, called PCA+RR, assumes that the 2D collocated patches extracted from all sub-aperture images to form a given patch-volume, are well aligned. This may not be the case when large disparities exist across sub-aperture images, depending on the depth of the scene and of the capturing device. For light fields exhibiting large disparities, the above method is further improved by using block matching (BM) to form patch-volumes with the best-matching patches across all sub-aperture images, instead of simply taking collocated patches. An iterative procedure is proposed where a different sub-aperture image is chosen as anchor at each iteration to form the patch-volumes. This method is referred to as BM+PCA+RR.
The dictionary of pairs of projected patch-volumes (the examples) map locally the relation between the high-resolution patchvolumes and their low-resolution (LR) counterparts. A linear mapping function is then learned, using Multivariate Ridge Regression (RR), between the subspaces of the low- and highresolution patch-volumes. Each overlapping patch-volume of the low-resolution light field can then be super-resolved by a straight application of the learned mapping function.
The above method, called PCA+RR, assumes that the 2D collocated patches extracted from all sub-aperture images to form a given patch-volume, are well aligned. This may not be the case when large disparities exist across sub-aperture images, depending on the depth of the scene and of the capturing device. For light fields exhibiting large disparities, the above method is further improved by using block matching (BM) to form patch-volumes with the best-matching patches across all sub-aperture images, instead of simply taking collocated patches. An iterative procedure is proposed where a different sub-aperture image is chosen as anchor at each iteration to form the patch-volumes. This method is referred to as BM+PCA+RR.
Results
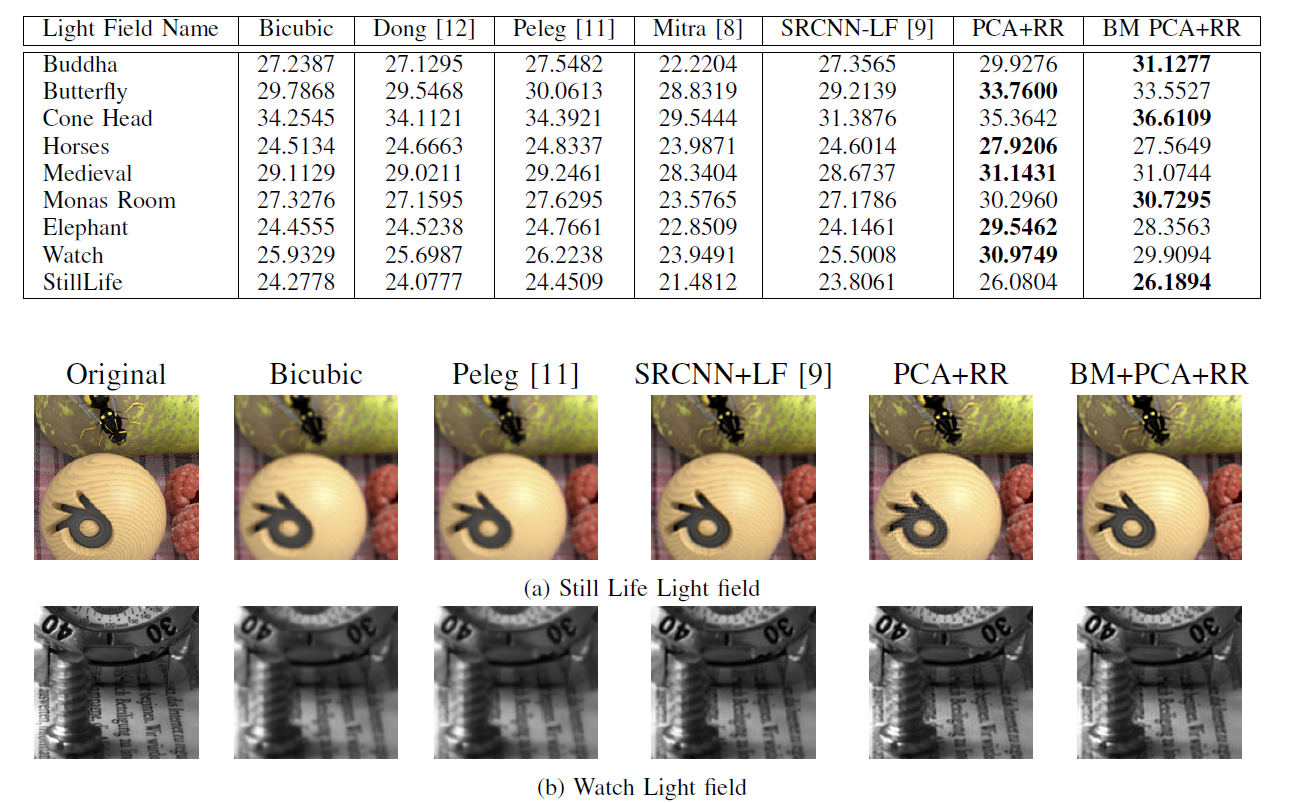
Spatial Super-resolution
In all the experiments involving spatial super-resolution, each sub-aperture image was blurred using a Gaussian filter of size
7x7 with standard deviation of 1.6 followed by downscaling
by a factor of 2. We train the projection matrix on 2000 patch volumes radomly extracted
from the training dataset (all the light fields except for the test light field). The performance of the proposed method was compared to single-image super-resolution schemes [11], [12], where these methods are applied on every sub-aperture image. It was
also compared against two light-field super-resolution methods
including the one of Mitra et. al. [8] and the deep convolutional network based
scheme[9].
 |
Angular Super-resolution
Left: Angular super-resolution with a deep convolutional network method. Right: Angular super-resolution with the proposed method.

To play the video click on the image | 
To play the video click on the image |
|---|