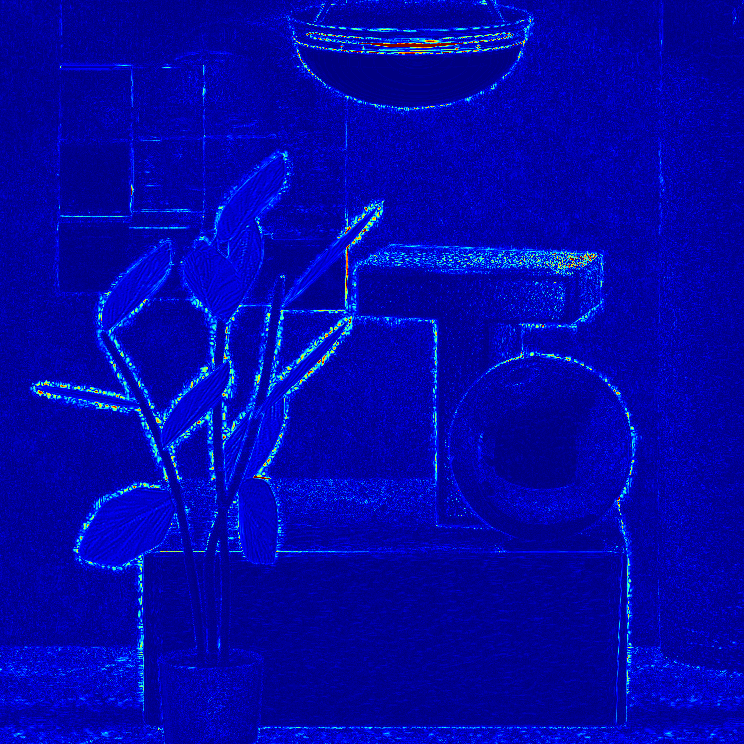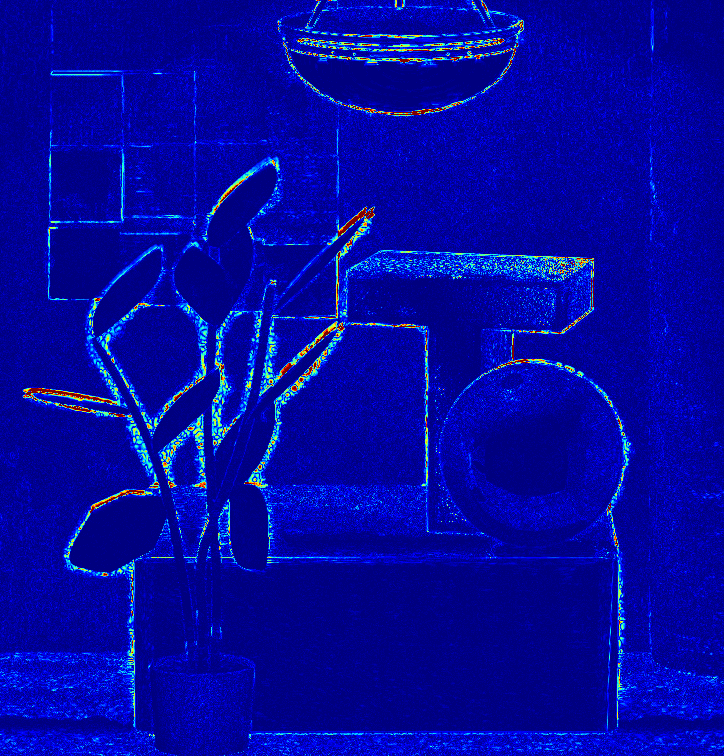In this paper, we propose a deep residual architecture that can be used both for synthesizing high quality angular views in light fields and temporal frames in classical videos.
The proposed framework consists of an optical flow estimator optimized for view synthesis, a trainable feature extractor and a residual convolutional network for pixel and feature-based view reconstruction.
Among these modules, the finetuning of the optical flow estimator specifically for the view synthesis task yields scene depth or motion information that is well optimized for the targeted problem.
In cooperation with the end-to-end trainable encoder, the synthesis block employs both pixel-based and feature-based synthesis with residual connection blocks, and the two synthesized views are fused with the help of a learned soft mask to obtain the final reconstructed view.
Experimental results with various datasets show that our method performs favorably against other state-of-the-art (SOTA) methods with a large gain for light field view synthesis.
Furthermore, with a little modification, our method can also be used for video frame interpolation, generating high quality frames compared with SOTA interpolation methods.
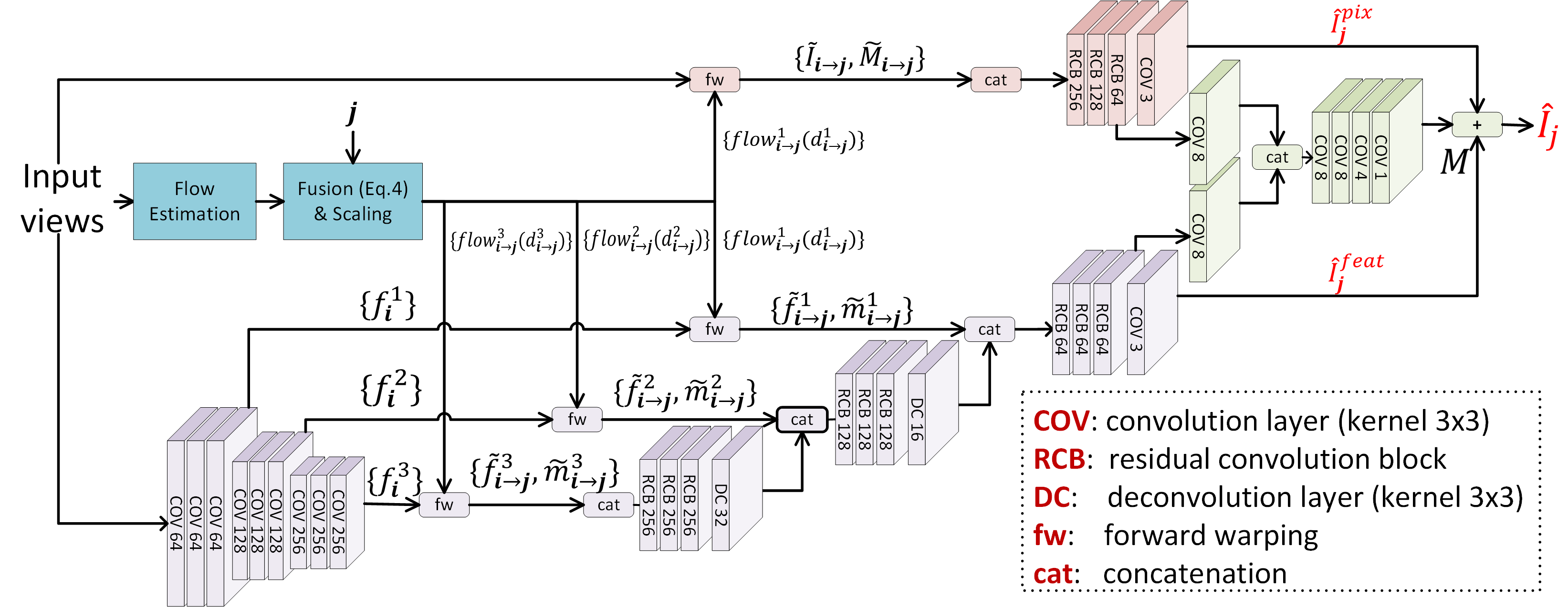
Algorithm overview
Overview of the proposed deep architecture for both light field view synthesis and video frame temporal interpolation.
In the case of the light field view synthesis problem, the input views are 4 sparse light field views (e.g. corner views) with i={tl,tr,bl,br} being the index of the source view positions, and j the index of the target view position.
In the case of video frame temporal interpolation, the input views are temporally adjacent views, with i={0,1} the index of source frame time instants, and j=t the target frame instant.
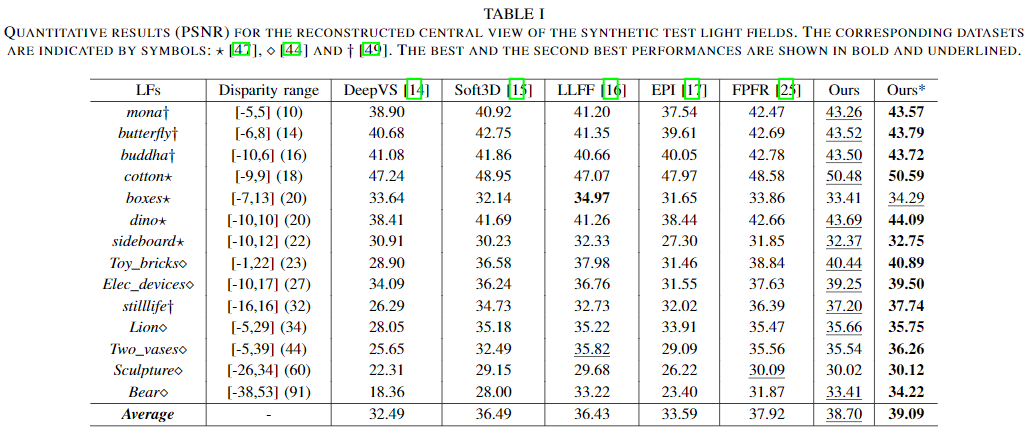
Quantitative assessment for LFVS (center view)
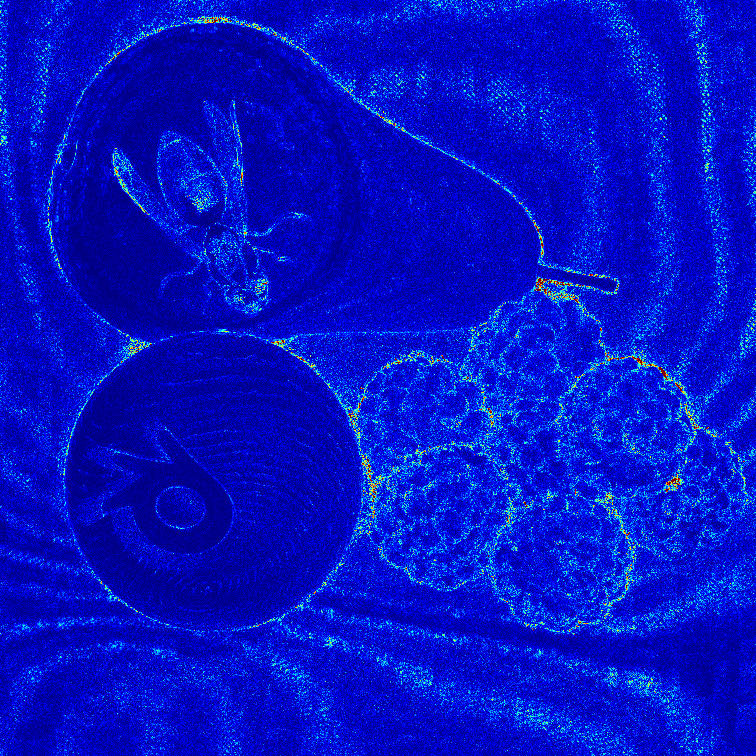
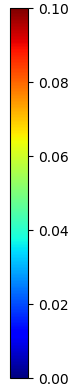
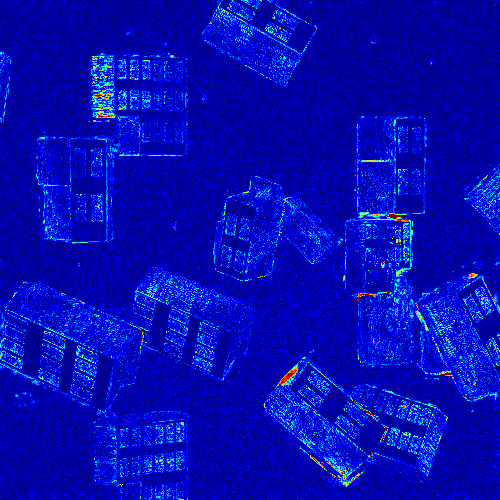
Visual comparison of the reconstruction error maps (center view)
Synthetic light fields
Stilllife
Buddha
MonasRoom
Sideboard
Cotton
Dino
Toy_bricks
GT
DeepVS
Soft3D
LLFF
EPI
FPFR
Ours
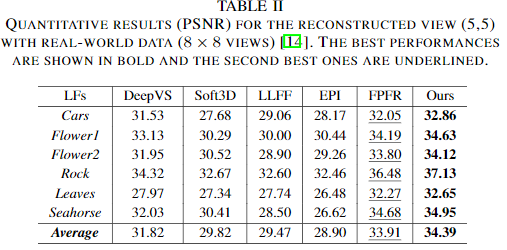
Real-world light fields
Flower1
Rock
Seahorse
GT
DeepVS
Soft3D
LLFF
EPI
FPFR
Ours
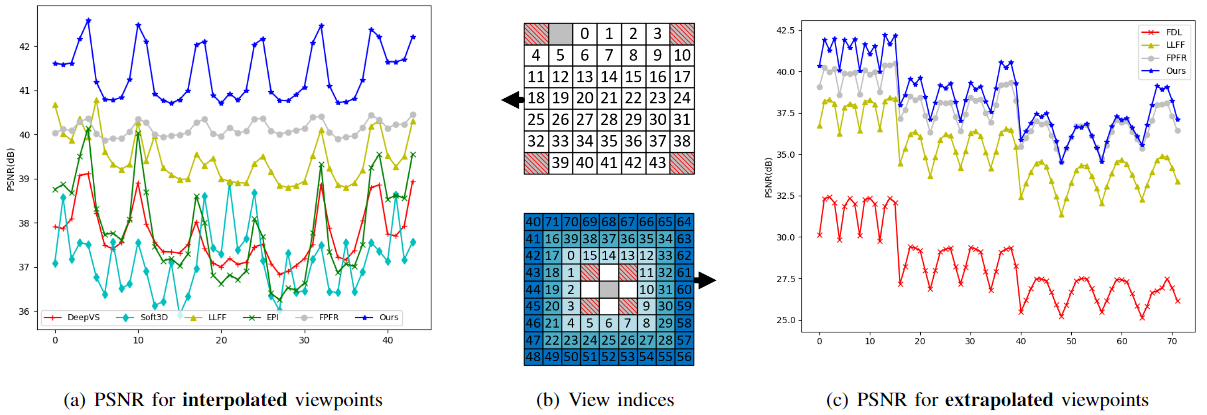
Performances for LFVS in terms of viewpoints
Averaged PSNR curves for the different viewpoints. (a) Interpolation. (c) Extrapolation. (b) View indices for interpolation (top) and extrapolation (bottom). 4 input views (red slash) are used for DeepVS, EPI, Soft3D, FPFR, FDL and our method, whereas 5 input views (grey) are used for LLFF.
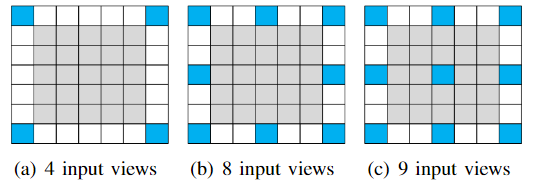
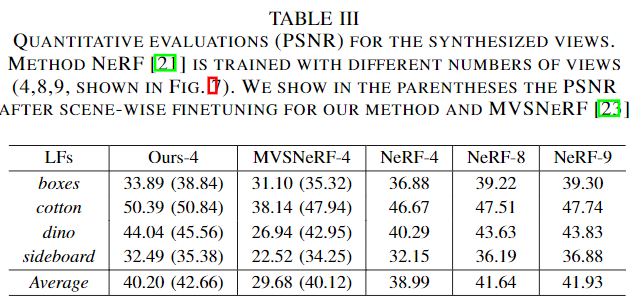
Comparison with Neural Radiance Field-based methods
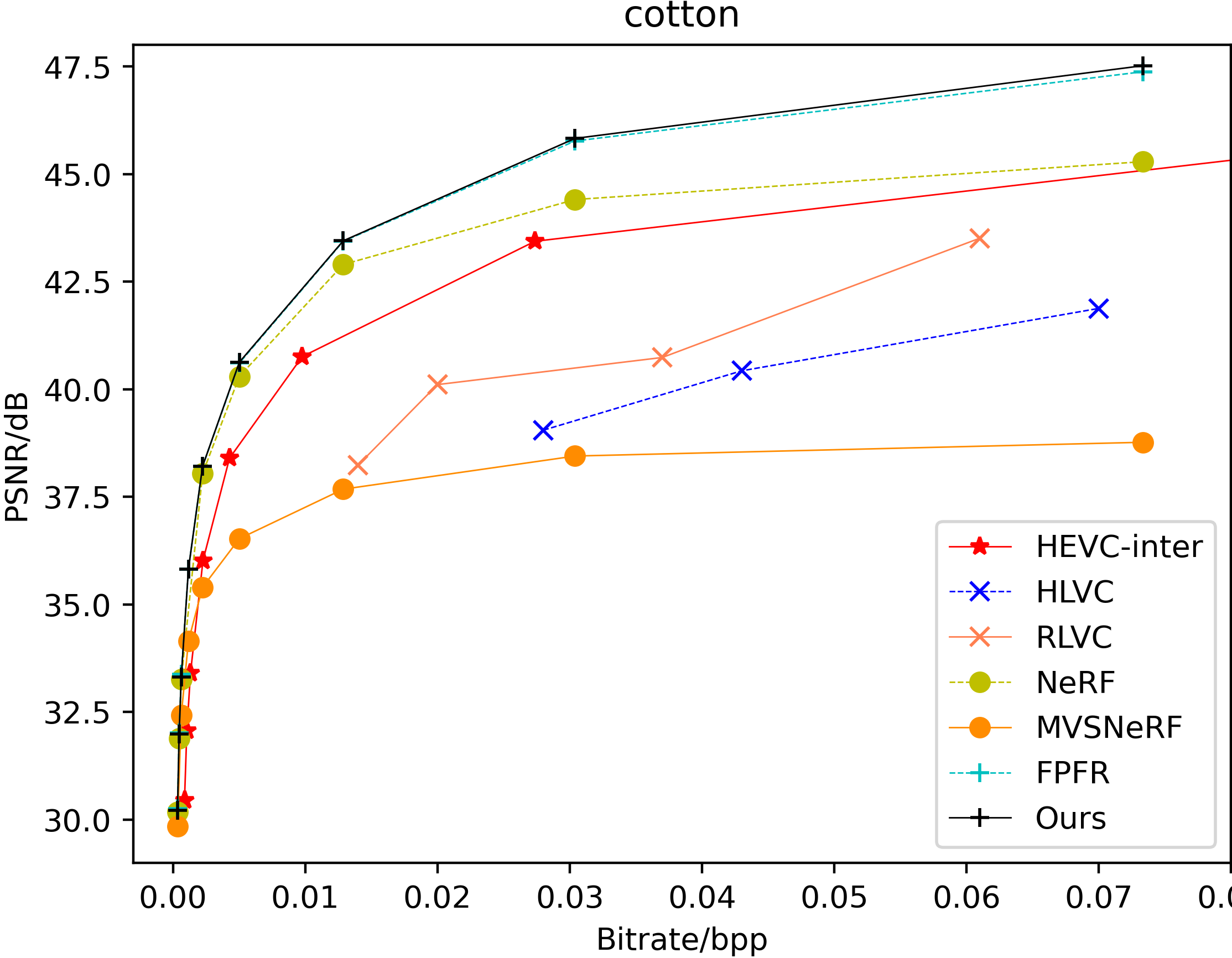
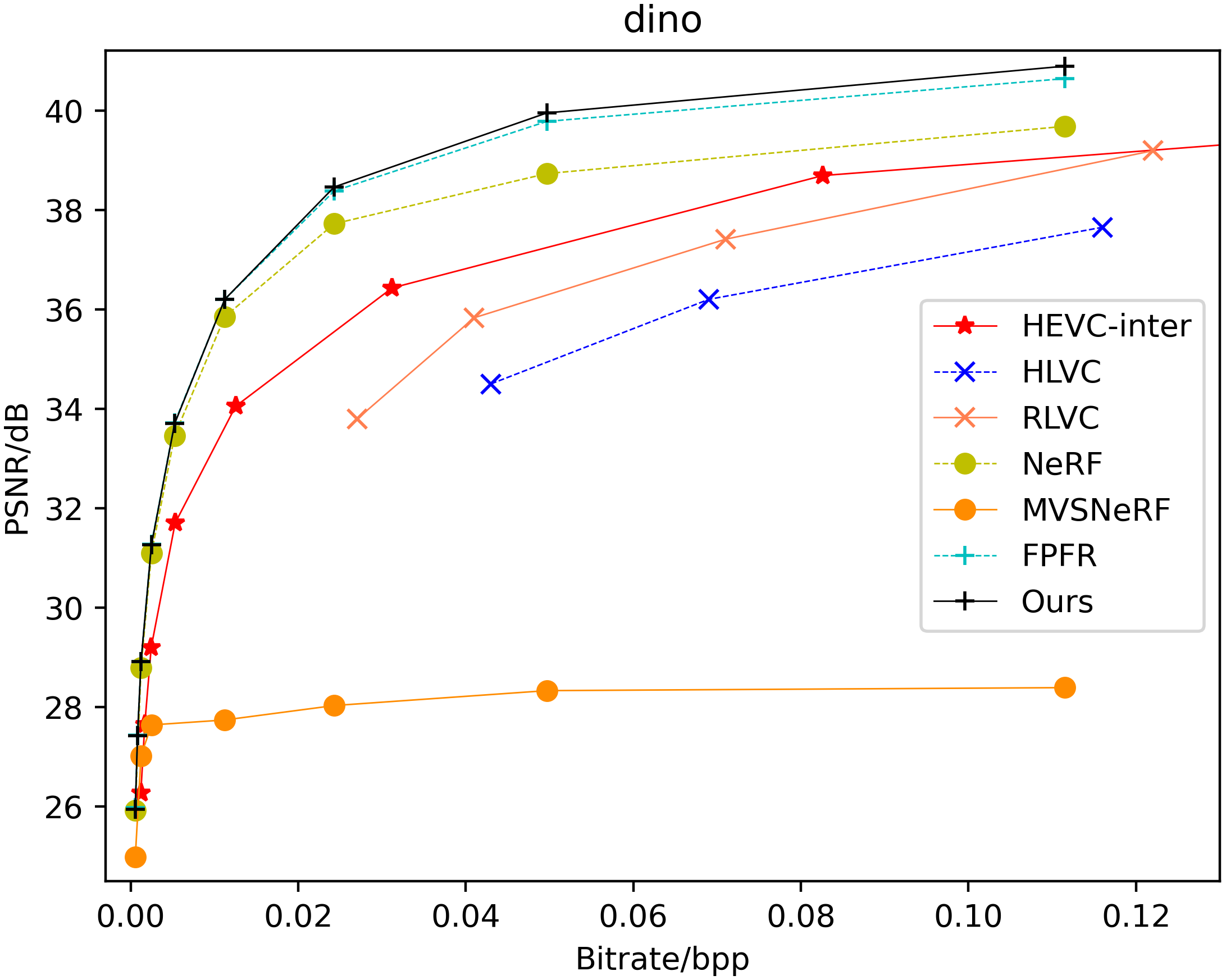
Compression performance analysis
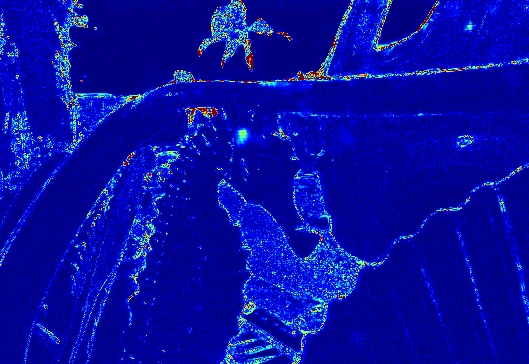
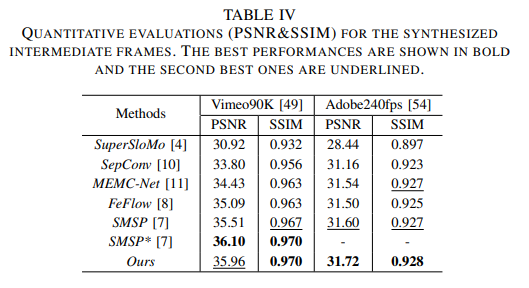
Quantitative assessment for VFI
Visual comparison of the interpolated frames
MEMC-Net
FeFlow
SMSP
Ours
GT
Additional results on Berkeley's dataset (up-convert video frame rate to 8X)
Videos taken from Wang, T. C., Zhu, J. Y., Kalantari, N. K., Efros, A. A., & Ramamoorthi, R. (2017). Light field video capture using a learning-based hybrid imaging system. ACM Transactions on Graphics (TOG), 36(4), 1-13. We take the central views of all key frames.
Hybrid/Sequence 02
Hybrid/Sequence 03
Hybrid/Sequence 04
References
DeepVS: N. Kalantari, T. Wang, and R. Ramamoorthi, "Learning-based view synthesis for light field cameras". ACM Trans. on Graphics (TOG), 2016
Soft3D: E. Penner and L. Zhang, "Soft 3D reconstruction for view synthesis". ACM Trans. on Graphics (TOG), 2017
LLFF: B. Mildenhall, P. Srinivasan, et al., "Local light field fusion: Practical view synthesis with prescriptive sampling guidelines". ACM Trans. on Graphics (TOG), 2019
EPI: G. Wu, Y. Liu, Q. Dai, and T. Chai, "Learning sheared epi structure for light field reconstruction". IEEE Trans. Image Process (TIP), 2019
FPFR: J. Shi, X. Jiang, and C. Guillemot, "Learning fused pixel and feature-based view reconstructions for light fields". In IEEE. Int. Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
SuperSloMo: H. Jiang, D. Sun, V. Jampani, J. Kautz, et al. "Super slomo: High quality estimation of multiple intermediate frames for video interpolation". In IEEE. Int. Conf. on Computer Vision and Pattern Recognition (CVPR), 2018.
SepConv: S. Niklaus, L. Mai, and F. Liu. "Video frame interpolation via adaptive separable convolution". In IEEE Int. Conf. on Computer Vision (ICCV), 2017.
MEMC: W. Bao, W. Lai, X. Zhang, M. Yang, et al. "Memc-net: Motion estimation and motion compensation driven neural network for video interpolation and enhancement". IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI),2019.
FeFlow: S. Gui, C. Wang, Q. Chen, and D. Tao. "Featureflow: Robust video interpolation via structure-to-texture generation". In IEEE. Int. Conf. on Computer Vision and Pattern Recognition (CVPR), 2020
SMSP: S. Niklaus and F. Liu. "Softmax splatting for video frame interpolation". In IEEE. Int. Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.